 第29章【高级篇】索引优化与查询优化
第29章【高级篇】索引优化与查询优化
# 【宋红康 MySQL数据库 】【高级篇】索引优化与查询优化
索引优化不必死记硬背,一切都是优化器基于成本的考虑。
# 哪些维度可以进行数据库调优

# 数据准备
#1. 数据准备
CREATE DATABASE atguigudb2;
USE atguigudb2;
#建表
CREATE TABLE `class` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`className` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
#CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
SET GLOBAL log_bin_trust_function_creators=1;
#随机产生字符串
DELIMITER //
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
#用于随机产生多少到多少的编号
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;
RETURN i;
END //
DELIMITER ;
#创建往stu表中插入数据的存储过程
DELIMITER //
CREATE PROCEDURE insert_stu( START INT , max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #设置手动提交事务
REPEAT #循环
SET i = i + 1; #赋值
INSERT INTO student (stuno, NAME ,age ,classId ) VALUES ((START+i),rand_string(6),rand_num(1,50),rand_num(1,1000));
UNTIL i = max_num
END REPEAT;
COMMIT; #提交事务
END //
DELIMITER ;
#执行存储过程,往class表添加随机数据
DELIMITER //
CREATE PROCEDURE `insert_class`( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class ( classname,address,monitor ) VALUES (rand_string(8),rand_string(10),rand_num(1,100000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
#执行存储过程,往class表添加1万条数据
CALL insert_class(10000);
#执行存储过程,往stu表添加50万条数据
CALL insert_stu(100000,500000);
SELECT COUNT(*) FROM class;
SELECT COUNT(*) FROM student;
# 删除某表上的索引 存储过程
DELIMITER //
CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT '';
DECLARE _cur CURSOR FOR SELECT index_name FROM information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND seq_in_index=1 AND index_name <>'PRIMARY' ;
#每个游标必须使用不同的declare continue handler for not found set done=1来控制游标的结束
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done=2 ;
#若没有数据返回,程序继续,并将变量done设为2
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>'' DO
SET @str = CONCAT("drop index " , _index , " on " , tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index='';
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END //
DELIMITER ;
# 执行存储过程
CALL proc_drop_index("dbname","tablename");
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
# 索引失效案例

# 全值匹配我最爱
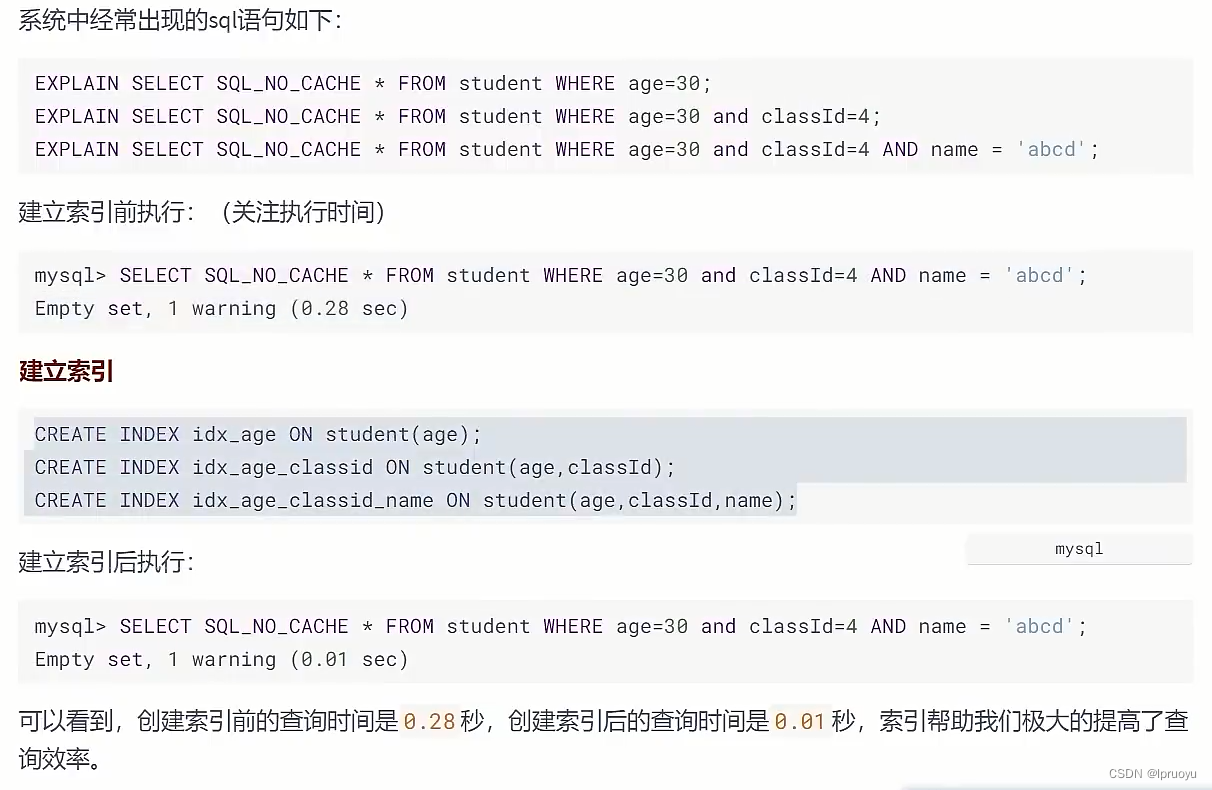
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = 'abcd';
SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = 'abcd';
CREATE INDEX idx_age ON student(age);
CREATE INDEX idx_age_classid ON student(age,classId);
CREATE INDEX idx_age_classid_name ON student(age,classId,NAME);
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 最佳左前缀法则

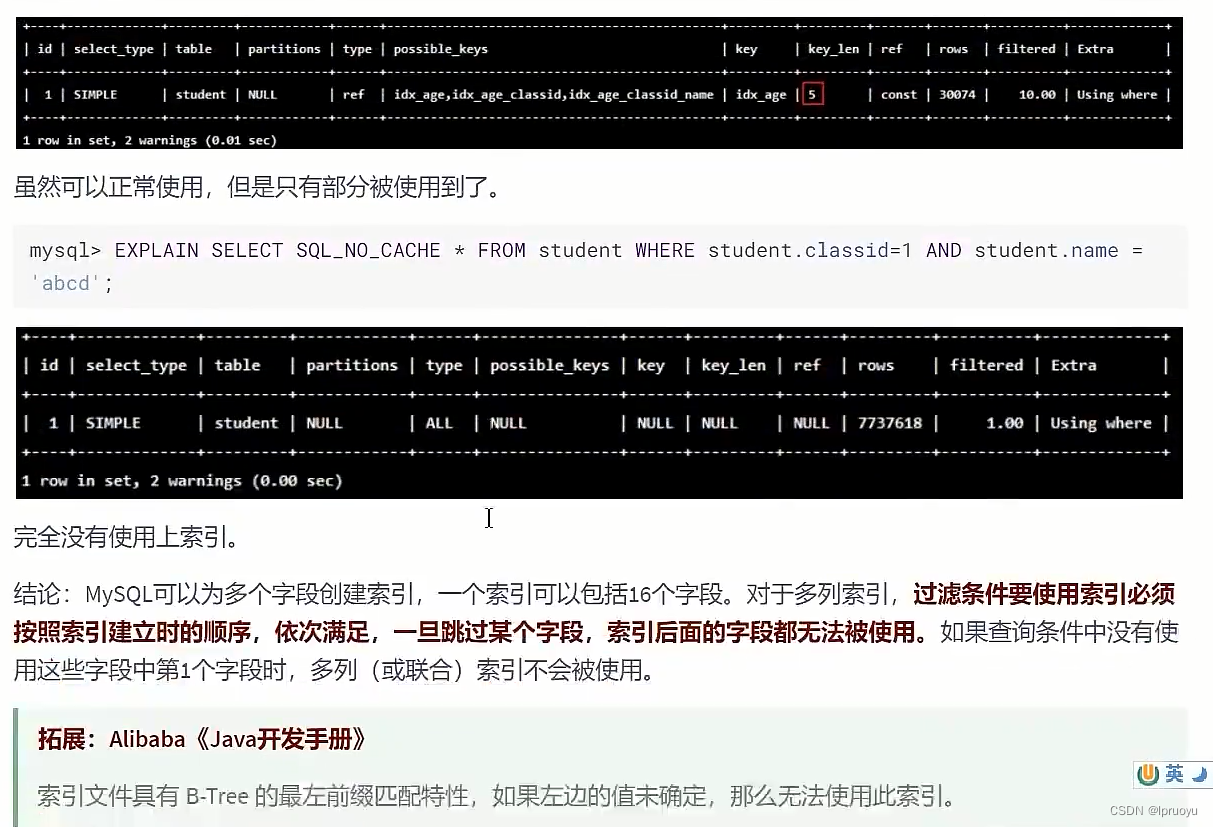
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abcd' ;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classid=1 AND student.name = 'abcd';
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE classid=4 AND student.age=30 AND student.name = 'abcd';
DROP INDEX idx_age ON student;
DROP INDEX idx_age_classid ON student;
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.name = 'abcd';
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
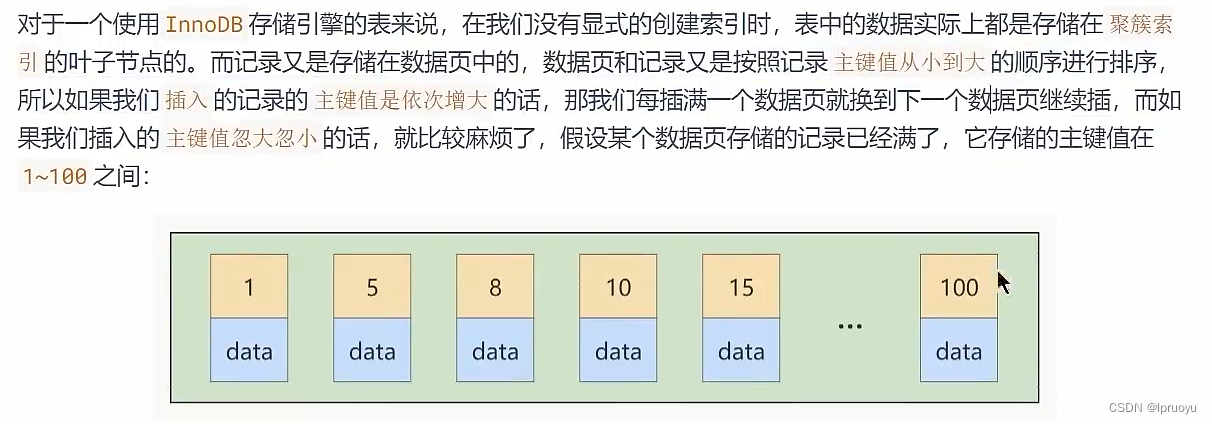
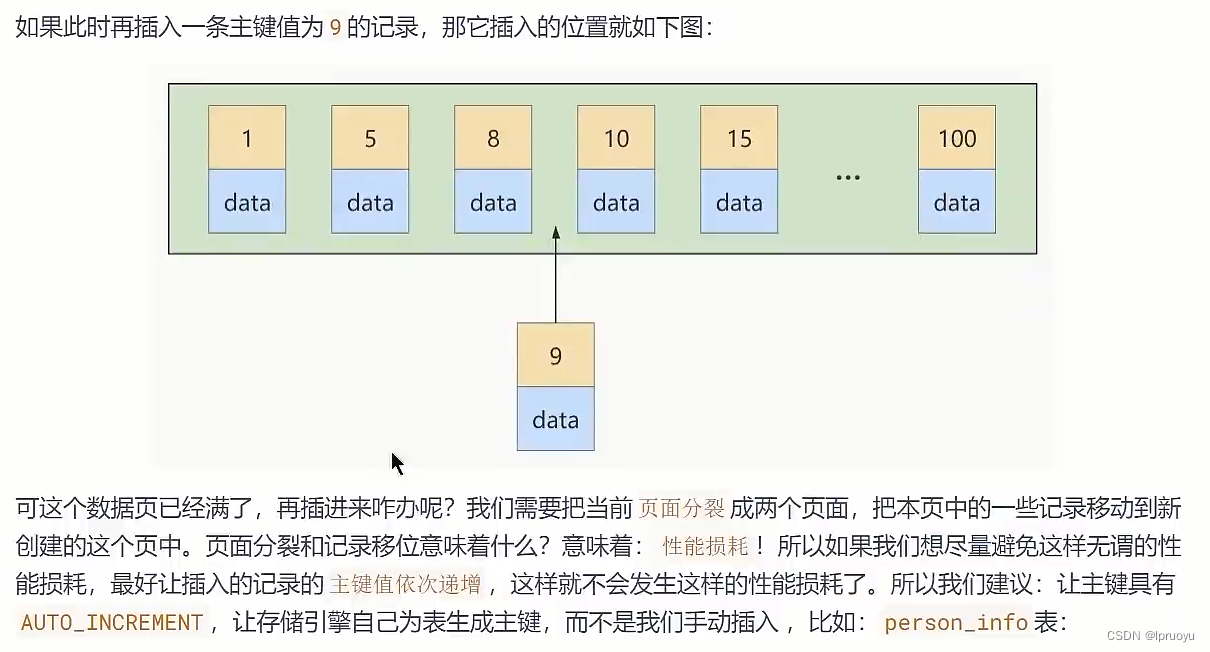
# 主键插入顺序
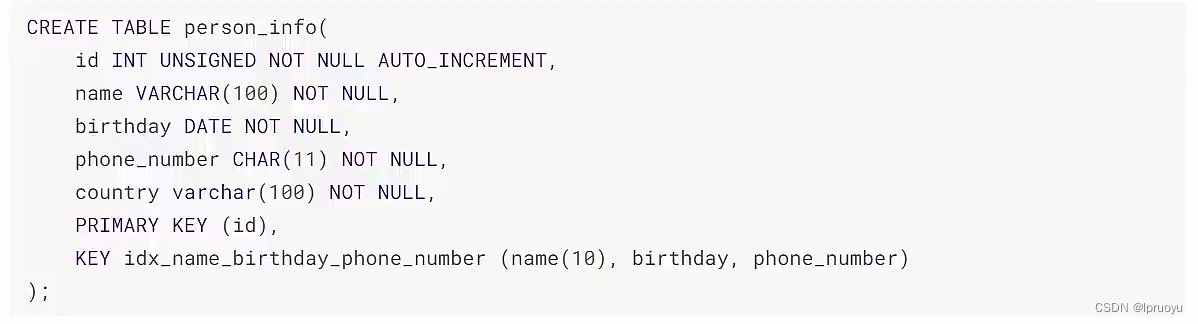

# 类型转换索引失效
# 计算、函数、类型转换(自动或手动)导致索引失效
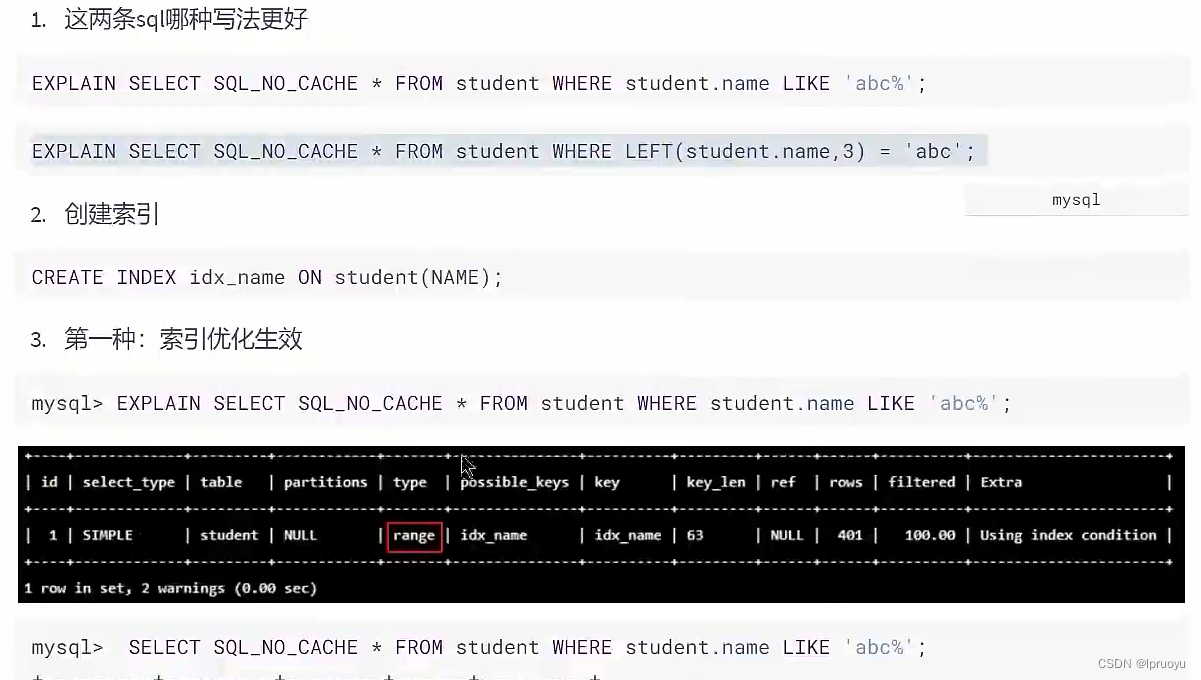
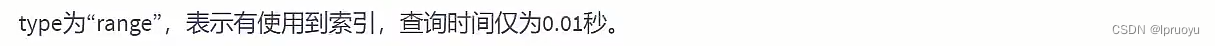

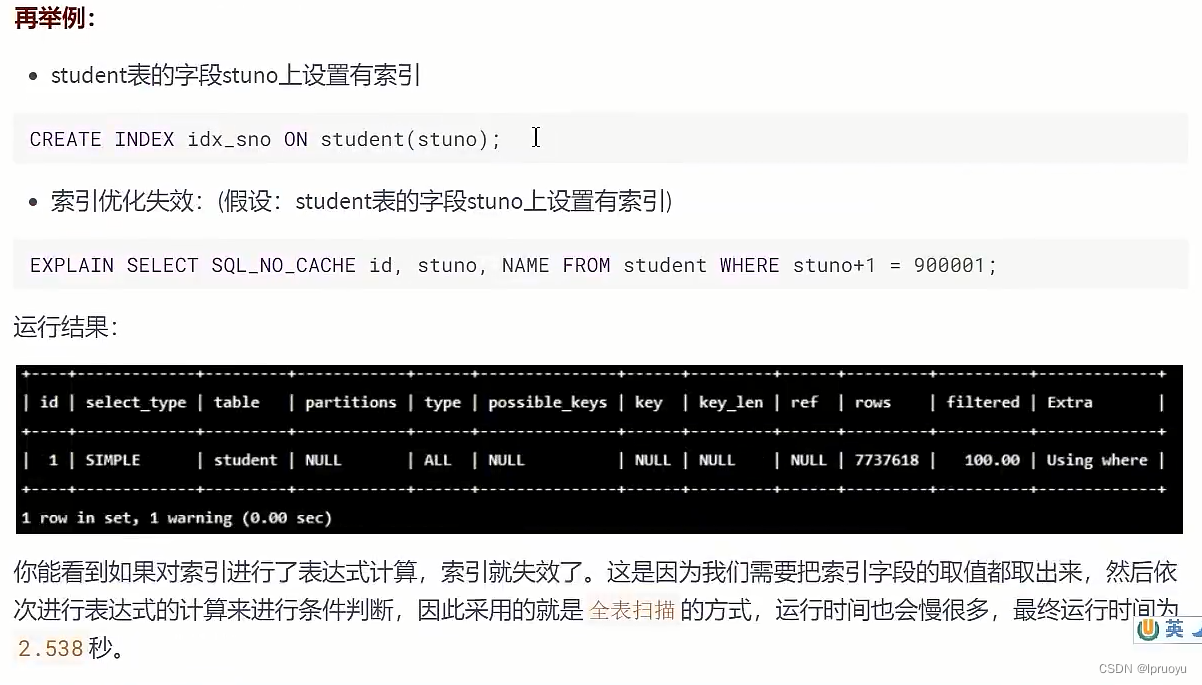


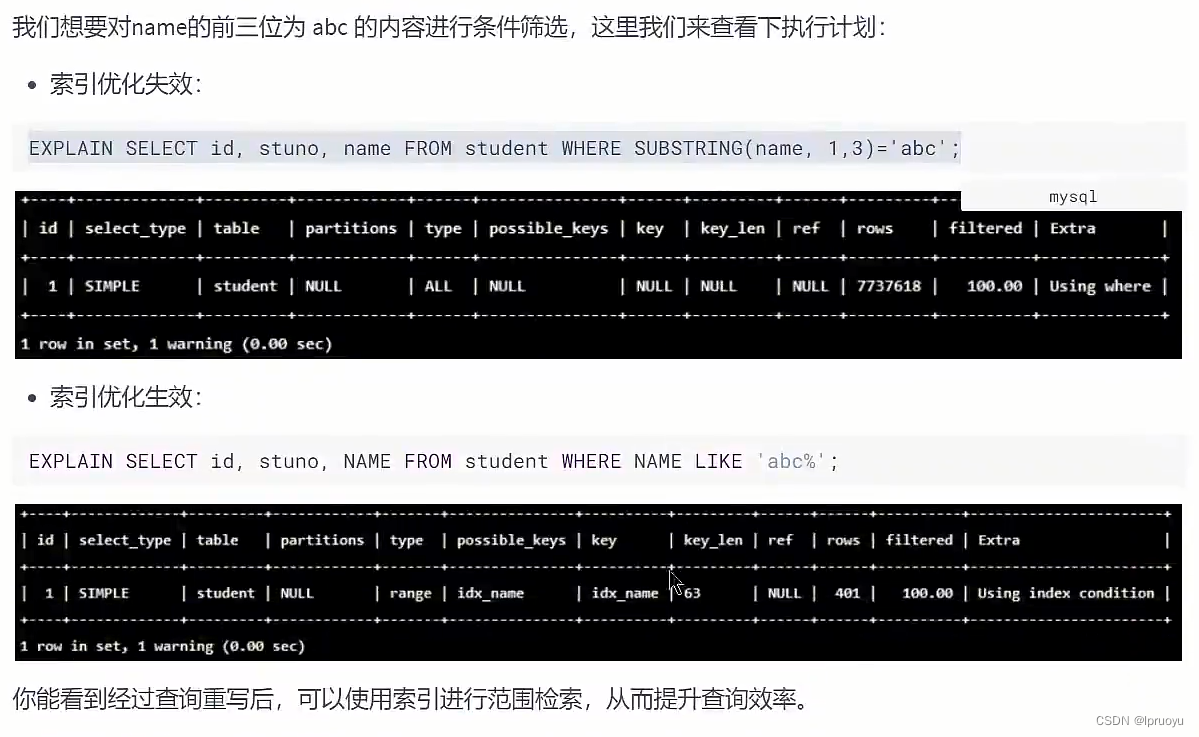
#此语句比下一条要好!(能够使用上索引)
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
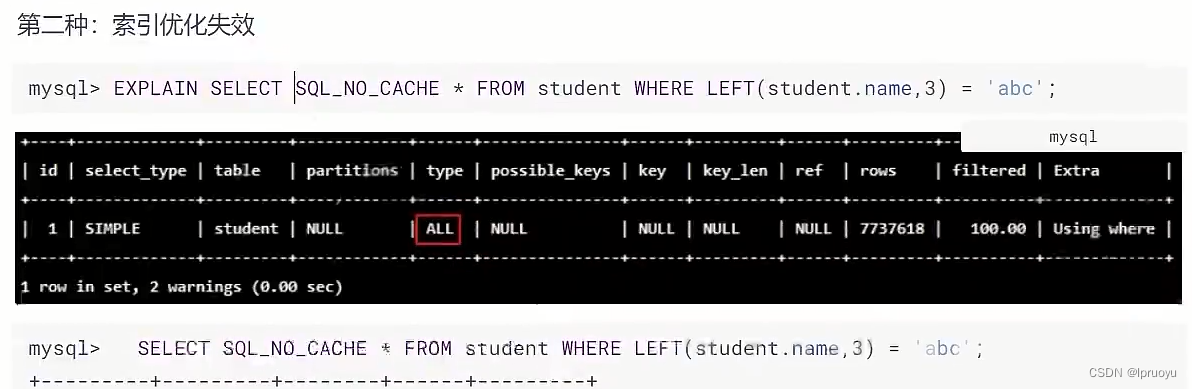
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
CREATE INDEX idx_name ON student(NAME);
CREATE INDEX idx_sno ON student(stuno);
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 900001;
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 900000;
EXPLAIN SELECT id, stuno, NAME FROM student WHERE SUBSTRING(NAME, 1,3)='abc';
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# 类型转换导致索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME = 123;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME = '123';
1
2
3
2
3

# 范围条件右边的列索引失效
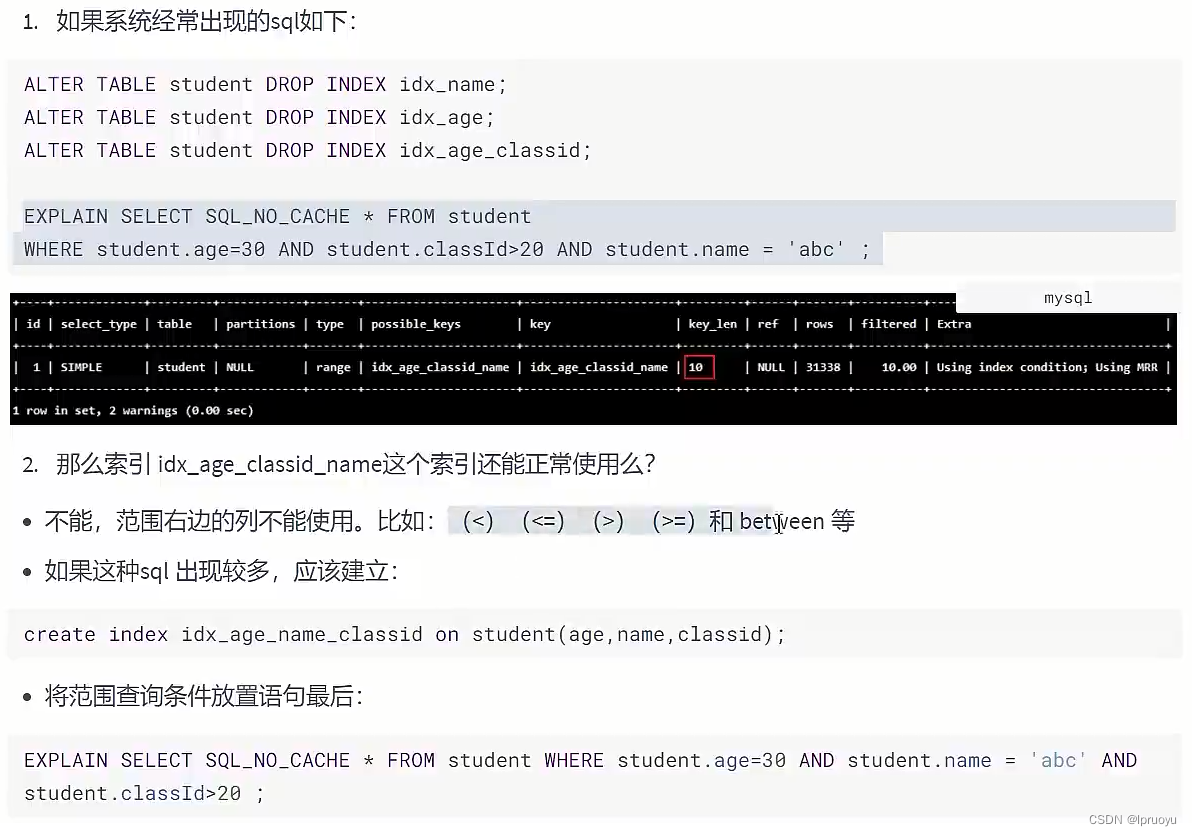

SHOW INDEX FROM student;
CALL proc_drop_index('atguigudb2','student');
CREATE INDEX idx_age_classId_name ON student(age,classId,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.classId>20 AND student.name = 'abc' ;
# 解决方案
CREATE INDEX idx_age_name_cid ON student(age,NAME,classId);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# 不等于索引失效
# 不等于(!= 或者<>)索引失效
CREATE INDEX idx_name ON student(NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name <> 'abc' ;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name != 'abc' ;
# 用到了索引
EXPLAIN SELECT SQL_NO_CACHE NAME FROM student WHERE student.name != 'abc' ;
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# is null可以使用索引,is not null无法使用索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;
1
2
3
2
3

# like以通配符%开头索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE 'ab%';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE '%ab%';
EXPLAIN SELECT * FROM student WHERE NAME LIKE '%abc';
EXPLAIN SELECT id,age FROM student WHERE NAME LIKE '%abc';
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8

# OR 前后存在非索引的列,索引失效
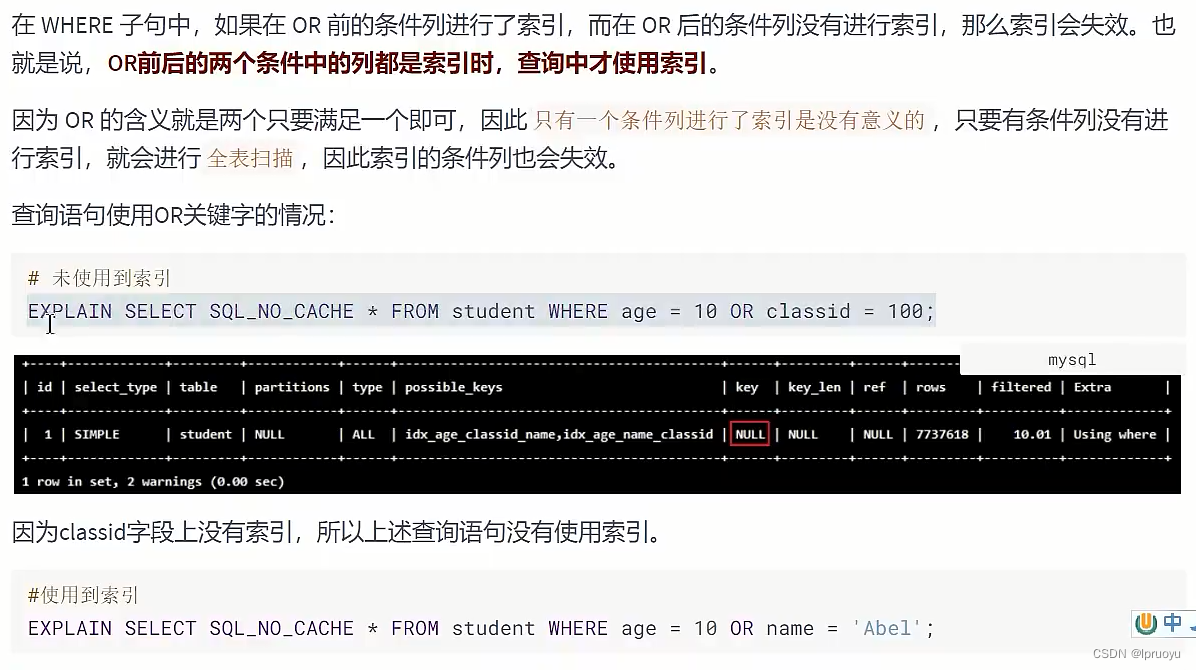

SHOW INDEX FROM student;
CALL proc_drop_index('atguigudb2','student');
CREATE INDEX idx_age ON student(age);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;
CREATE INDEX idx_cid ON student(classid);
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# 数据库和表的字符集统一使用utf8mb4

# 练习及一般性建议



# 关联查询优化
# 数据准备
#分类
CREATE TABLE IF NOT EXISTS `type` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
#图书
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
#向分类表中添加20条记录
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
#向图书表中添加20条记录
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
# 代码测试
# 情况1:左外连接
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
#添加索引
CREATE INDEX Y ON book(card);
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
CREATE INDEX X ON `type`(card);
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
DROP INDEX Y ON book;
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
# 情况2:内连接
DROP INDEX X ON `type`;
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;
#添加索引
CREATE INDEX Y ON book(card);
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;
CREATE INDEX X ON `type`(card);
#结论:对于内连接来说,查询优化器可以决定谁作为驱动表,谁作为被驱动表出现的
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;
#删除索引
DROP INDEX Y ON book;
#结论:对于内连接来讲,如果表的连接条件中只能有一个字段有索引,则有索引的字段所在的表会被作为被驱动表出现。
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;
CREATE INDEX Y ON book(card);
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;
#向type表中添加数据(20条数据)
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
#结论:对于内连接来说,在两个表的连接条件都存在索引的情况下,会选择小表作为驱动表。“小表驱动大表”
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
# JOIN的底层原理

# 驱动表和被驱动表
上边是驱动表
下边是被驱动表
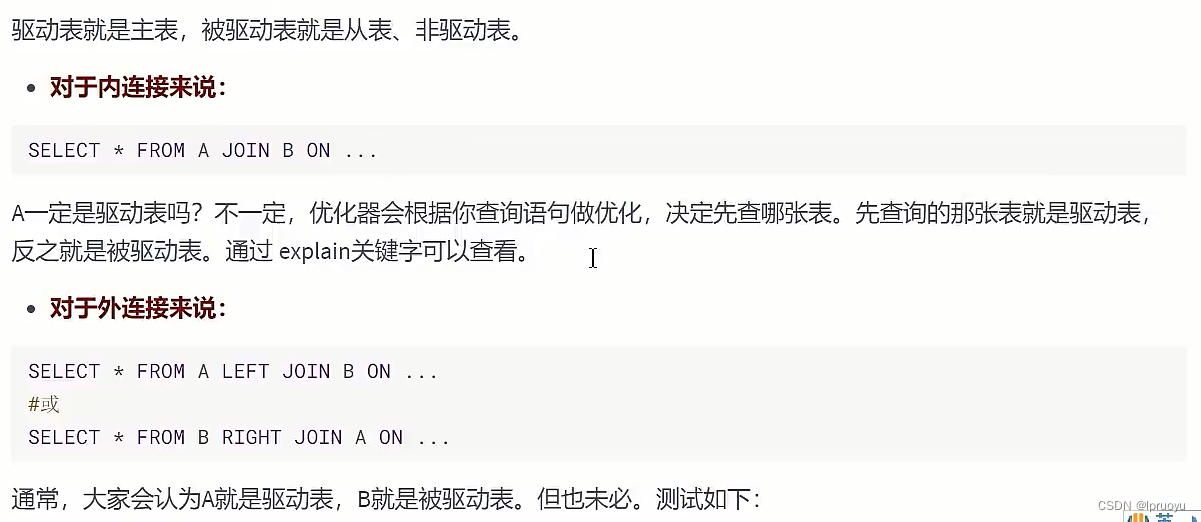
CREATE TABLE a(f1 INT, f2 INT, INDEX(f1))ENGINE=INNODB;
CREATE TABLE b(f1 INT, f2 INT)ENGINE=INNODB;
INSERT INTO a VALUES(1,1),(2,2),(3,3),(4,4),(5,5),(6,6);
INSERT INTO b VALUES(3,3),(4,4),(5,5),(6,6),(7,7),(8,8);
#测试1 # 优化器有可能会将外连接优化为内连接,既然是内连接了所以谁是驱动表都是有可能的
EXPLAIN SELECT * FROM a LEFT JOIN b ON(a.f1=b.f1) WHERE (a.f2=b.f2);
#测试2
EXPLAIN SELECT * FROM a LEFT JOIN b ON(a.f1=b.f1) AND (a.f2=b.f2);
#测试3
EXPLAIN SELECT * FROM a JOIN b ON(a.f1=b.f1) WHERE (a.f2=b.f2);
SHOW VARIABLES LIKE '%optimizer_switch%';
SHOW VARIABLES LIKE '%join_buffer%';
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 简单嵌套循环连接(Simple Nested-Loop Join)
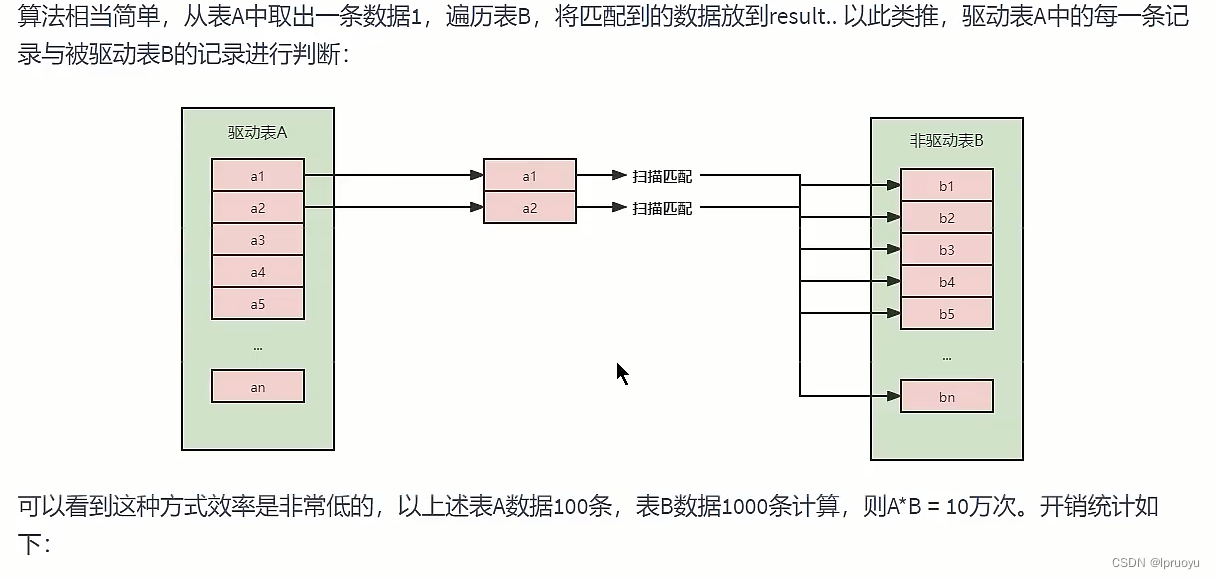
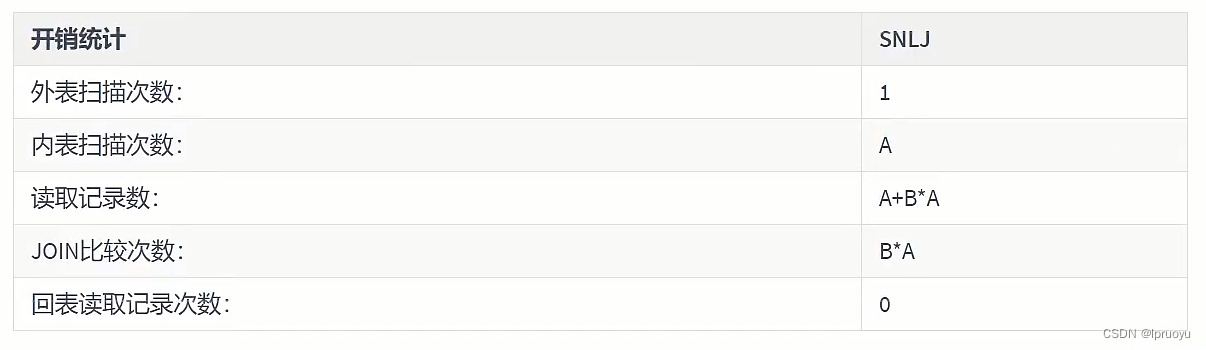

# 索引嵌套循环连接(Index Nested-Loop Join)

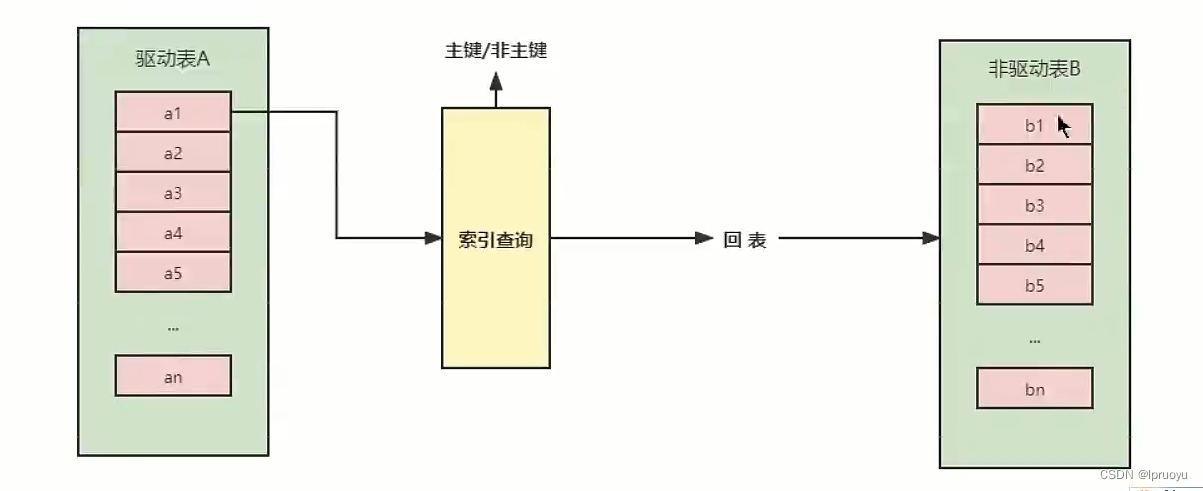
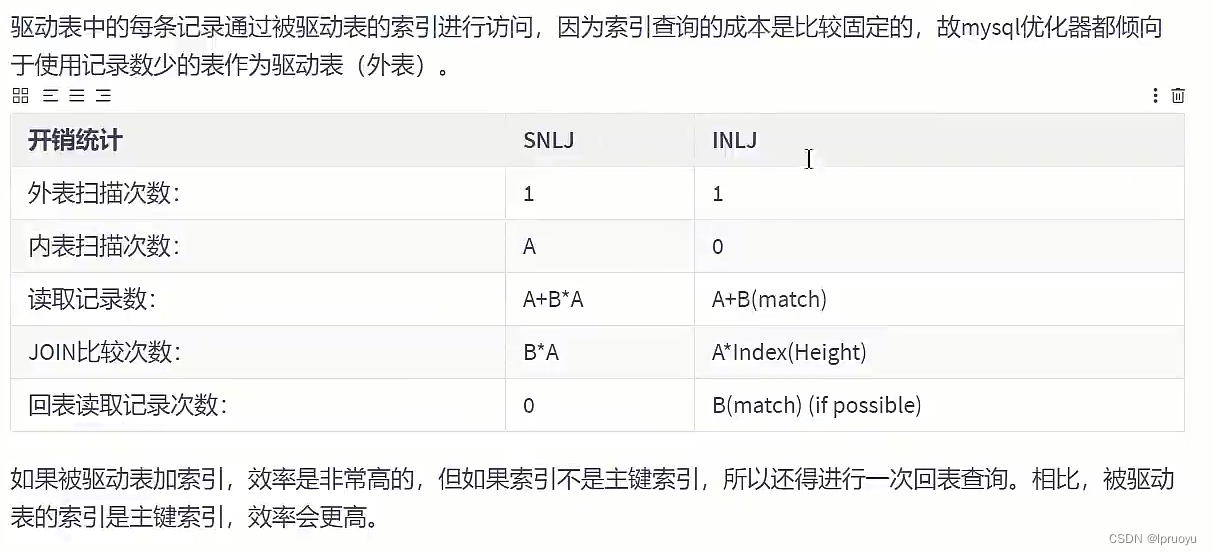
# 块嵌套循环连接(Block Nested-Loop Join)


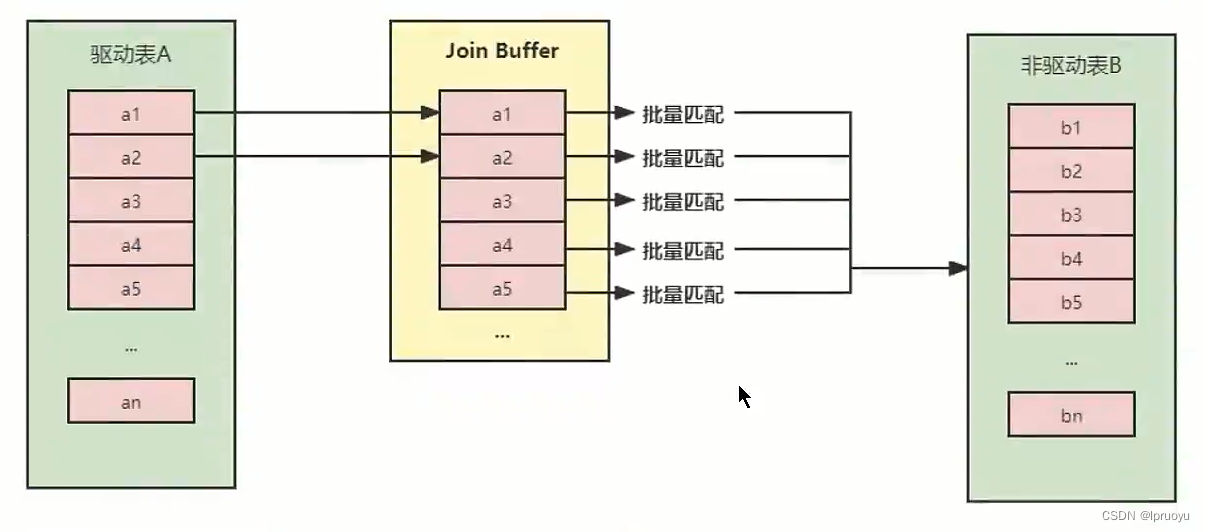
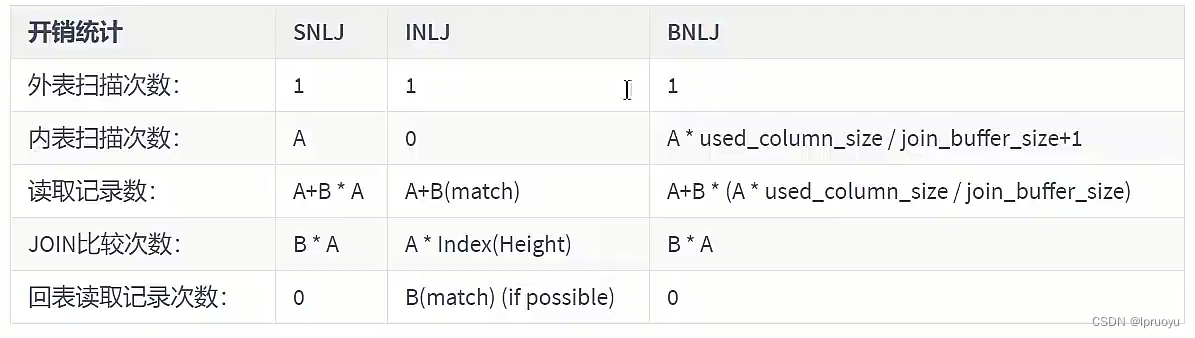


# Hash JOIN


# JOIN小结



# 子查询优化

#创建班级表中班长的索引
CREATE INDEX idx_monitor ON class(monitor);
#查询班长的信息
# 子查询
EXPLAIN SELECT * FROM student stu1
WHERE stu1.`stuno` IN (
SELECT monitor
FROM class c
WHERE monitor IS NOT NULL
);
# 多表查询
EXPLAIN SELECT stu1.* FROM student stu1 JOIN class c
ON stu1.`stuno` = c.`monitor`
WHERE c.`monitor` IS NOT NULL;
#查询不为班长的学生信息
# 子查询
EXPLAIN SELECT SQL_NO_CACHE a.*
FROM student a
WHERE a.stuno NOT IN (
SELECT monitor FROM class b
WHERE monitor IS NOT NULL)
# 多表查询
EXPLAIN SELECT SQL_NO_CACHE a.*
FROM student a LEFT OUTER JOIN class b
ON a.stuno =b.monitor
WHERE b.monitor IS NULL;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32

# 排序优化
# 排序优化

# 代码测试
#删除student和class表中的非主键索引
CALL proc_drop_index('atguigudb2','student');
CALL proc_drop_index('atguigudb2','class');
SHOW INDEX FROM student;
SHOW INDEX FROM class;
#过程一:
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid;
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid LIMIT 10;
#过程二:order by时不limit,索引失效
#创建索引
CREATE INDEX idx_age_classid_name ON student (age,classid,NAME);
#不限制,索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid;
#EXPLAIN SELECT SQL_NO_CACHE age,classid,name,id FROM student ORDER BY age,classid;
#增加limit过滤条件,使用上索引了。
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid LIMIT 10;
#过程三:order by时顺序错误,索引失效
#创建索引age,classid,stuno
CREATE INDEX idx_age_classid_stuno ON student (age,classid,stuno);
#以下哪些索引失效?
EXPLAIN SELECT * FROM student ORDER BY classid LIMIT 10;
EXPLAIN SELECT * FROM student ORDER BY classid,NAME LIMIT 10;
EXPLAIN SELECT * FROM student ORDER BY age,classid,stuno LIMIT 10;
EXPLAIN SELECT * FROM student ORDER BY age,classid LIMIT 10;
EXPLAIN SELECT * FROM student ORDER BY age LIMIT 10;
#过程四:order by时规则不一致, 索引失效 (顺序错,不索引;方向反,不索引)
EXPLAIN SELECT * FROM student ORDER BY age DESC, classid ASC LIMIT 10;
EXPLAIN SELECT * FROM student ORDER BY classid DESC, NAME DESC LIMIT 10;
EXPLAIN SELECT * FROM student ORDER BY age ASC,classid DESC LIMIT 10;
EXPLAIN SELECT * FROM student ORDER BY age DESC, classid DESC LIMIT 10;
#过程五:无过滤,不索引
EXPLAIN SELECT * FROM student WHERE age=45 ORDER BY classid;
EXPLAIN SELECT * FROM student WHERE age=45 ORDER BY classid,NAME;
EXPLAIN SELECT * FROM student WHERE classid=45 ORDER BY age;
EXPLAIN SELECT * FROM student WHERE classid=45 ORDER BY age LIMIT 10;
CREATE INDEX idx_cid ON student(classid);
EXPLAIN SELECT * FROM student WHERE classid=45 ORDER BY age;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56

# 测试filesort和index排序
CALL proc_drop_index('atguigudb2','student');
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
#方案一: 为了去掉filesort我们可以把索引建成
CREATE INDEX idx_age_name ON student(age,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
#方案二:
CREATE INDEX idx_age_stuno_name ON student(age,stuno,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
DROP INDEX idx_age_stuno_name ON student;
CREATE INDEX idx_age_stuno ON student(age,stuno);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19

# filesort算法:双路排序和单路排序



# Group By优化

# 分页查询优化
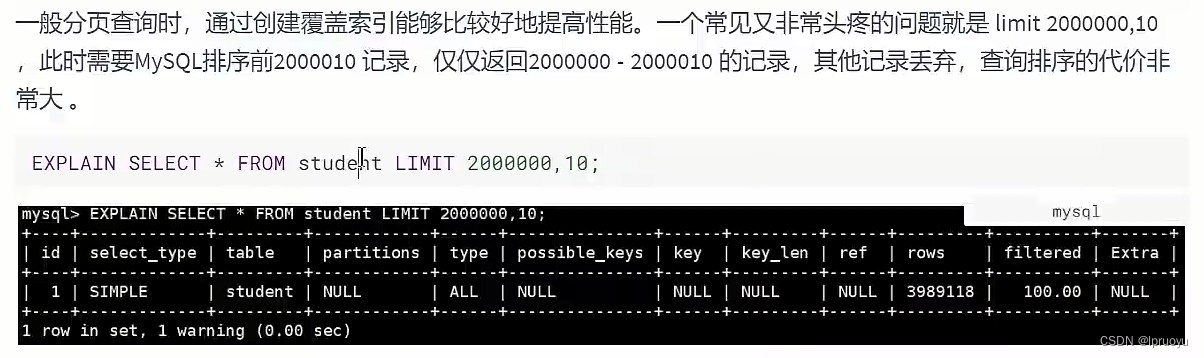
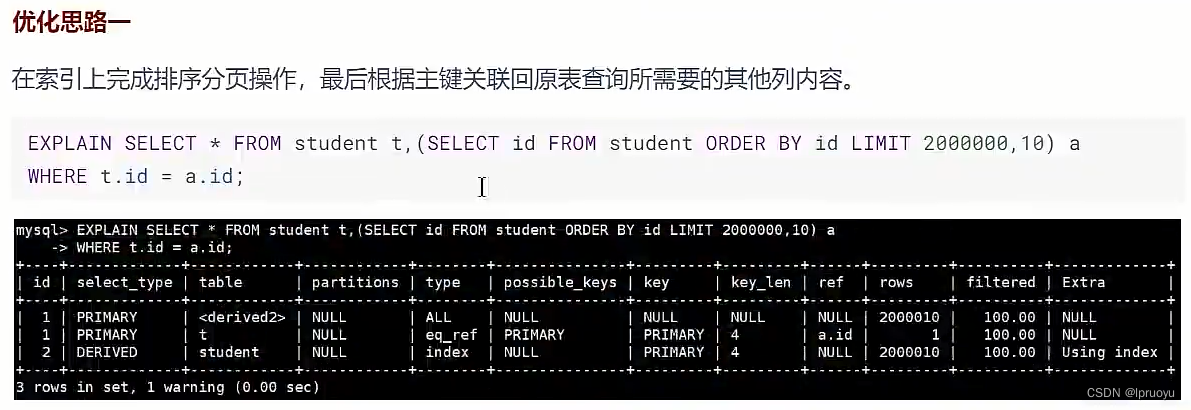
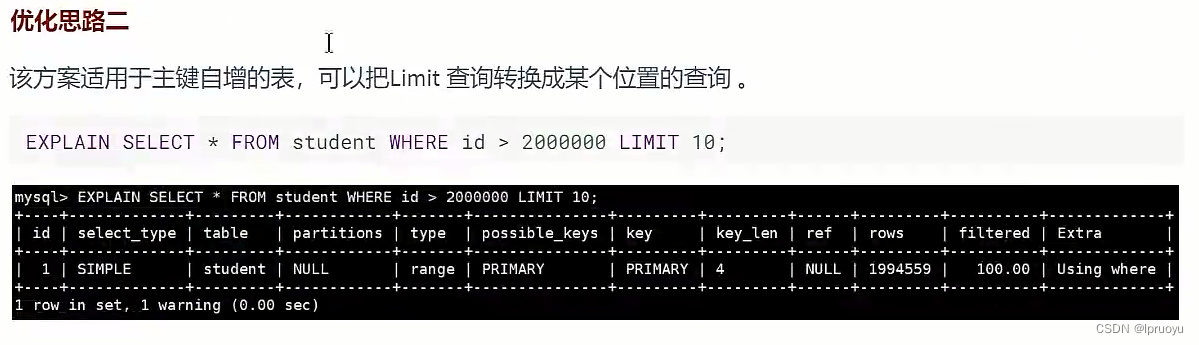
# 优先考虑覆盖索引
# 什么是覆盖索引

#删除之前的索引
#举例1:
DROP INDEX idx_age_stuno ON student;
CREATE INDEX idx_age_name ON student (age,NAME);
EXPLAIN SELECT * FROM student WHERE age <> 20;
EXPLAIN SELECT age,NAME FROM student WHERE age <> 20;
#举例2:
EXPLAIN SELECT * FROM student WHERE NAME LIKE '%abc';
EXPLAIN SELECT id,age FROM student WHERE NAME LIKE '%abc';
###
SELECT CRC32('hello')
FROM DUAL;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 覆盖索引的利弊

# 索引下推(索引条件下推)
# 使用前后对比

# ICP的开启/关闭

SET optimizer_switch = 'index_condition_pushdown=on';
1
# 代码测试
#举例1:
USE atguigudb1;
EXPLAIN SELECT * FROM s1 WHERE key1 > 'z' AND key1 LIKE '%a';
#举例2:
CREATE TABLE `people` (
`id` INT NOT NULL AUTO_INCREMENT,
`zipcode` VARCHAR(20) COLLATE utf8_bin DEFAULT NULL,
`firstname` VARCHAR(20) COLLATE utf8_bin DEFAULT NULL,
`lastname` VARCHAR(20) COLLATE utf8_bin DEFAULT NULL,
`address` VARCHAR(50) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `zip_last_first` (`zipcode`,`lastname`,`firstname`)
) ENGINE=INNODB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb3 COLLATE=utf8_bin;
INSERT INTO `people` VALUES
('1', '000001', '三', '张', '北京市'),
('2', '000002', '四', '李', '南京市'),
('3', '000003', '五', '王', '上海市'),
('4', '000001', '六', '赵', '天津市');
EXPLAIN SELECT * FROM people
WHERE zipcode='000001'
AND lastname LIKE '%张%'
AND address LIKE '%北京市%';
EXPLAIN SELECT * FROM people
WHERE zipcode='000001'
AND lastname LIKE '张%'
AND firstname LIKE '三%';
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 开启和关闭ICP的性能对比
#创建存储过程,向people表中添加1000000条数据,测试ICP开启和关闭状态下的性能
DELIMITER //
CREATE PROCEDURE insert_people( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO people ( zipcode,firstname,lastname,address ) VALUES ('000001', '六', '赵', '天津市');
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
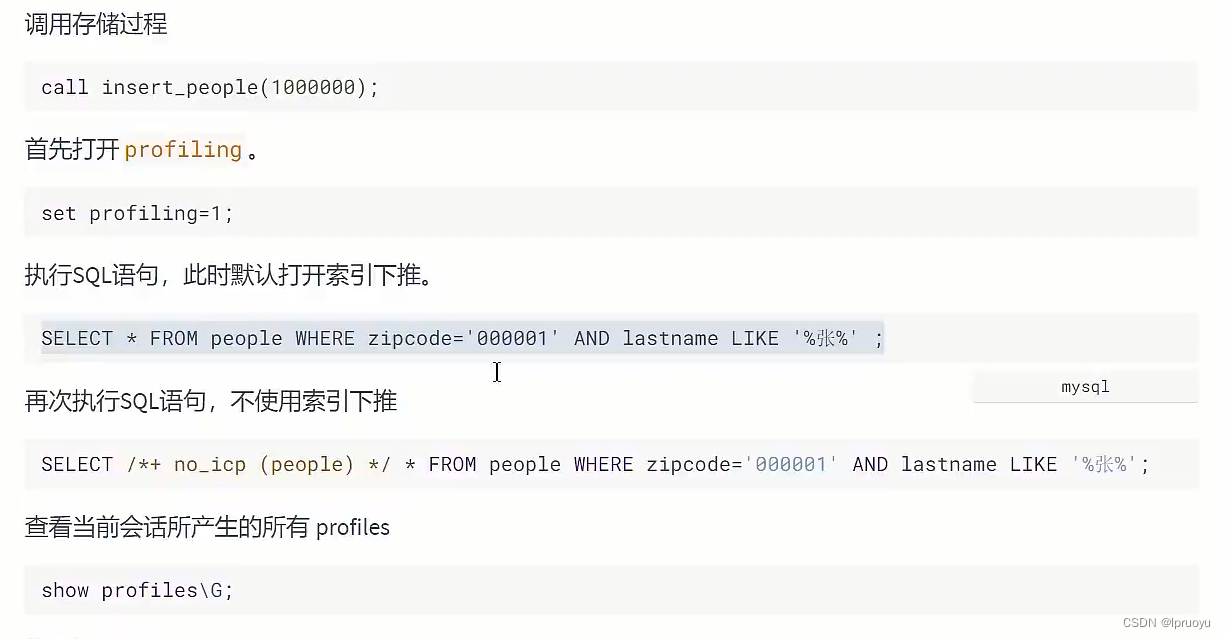
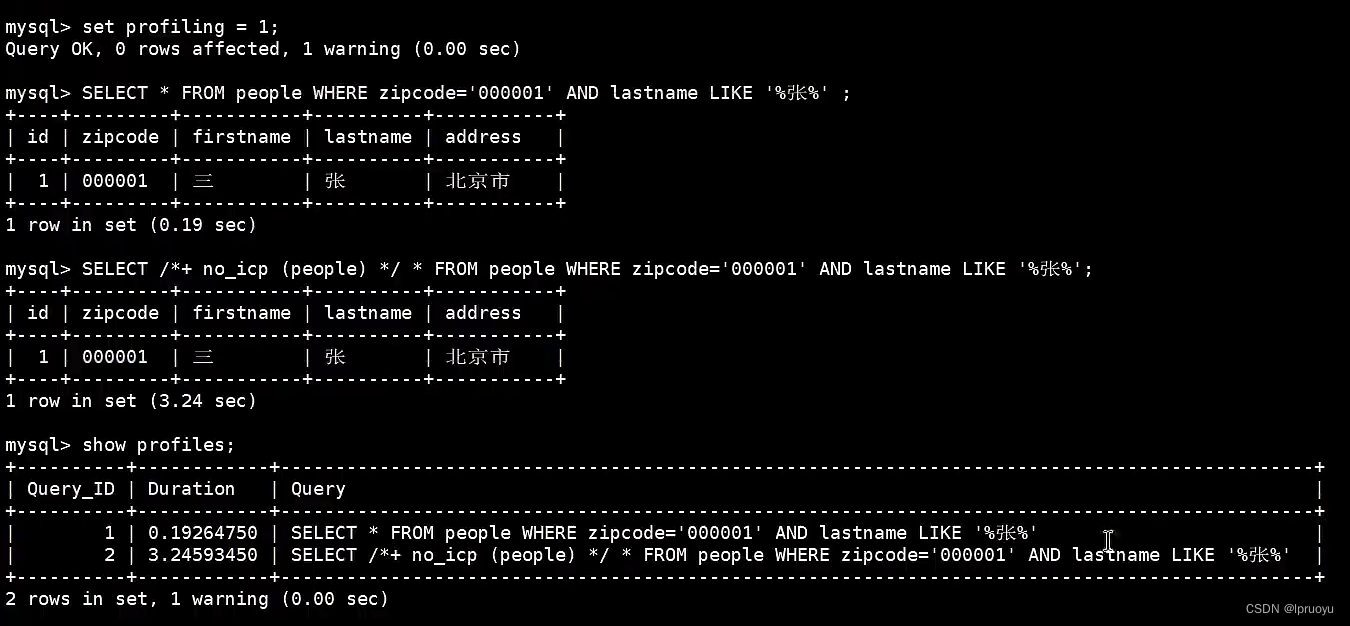
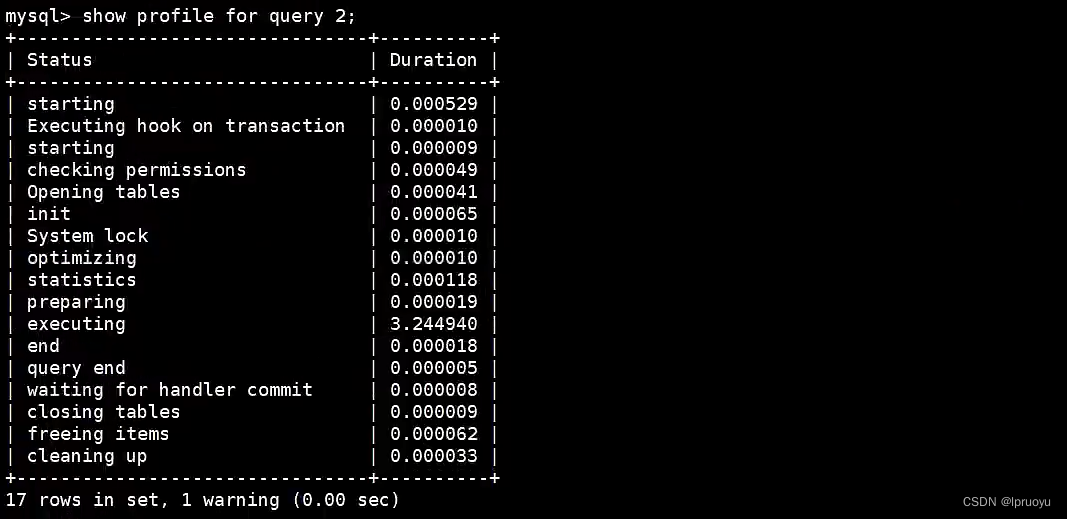
# ICP的使用条件
不需要回表的话,ICP就用不上了。

# 其他查询优化策略
# EXISTS和IN的区分
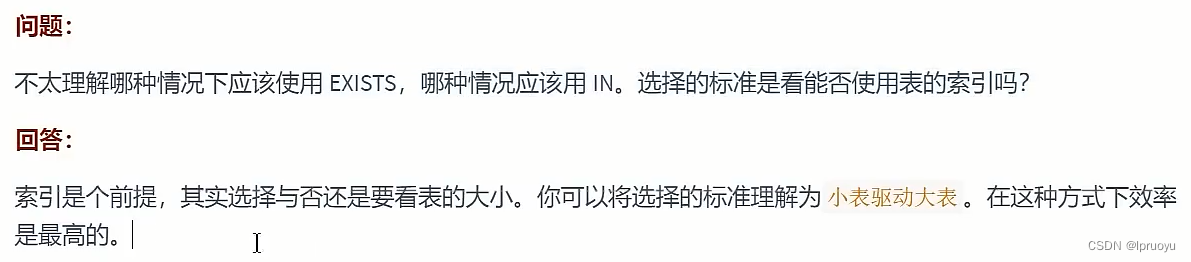

# COUNT(*)与COUNT(具体字段)效率

# 关于SELECT(*)

# LIMIT 1对优化的影响

# 多使用COMMIT

# 淘宝数据库主键是如何设计的?

# 自增ID的问题


# 业务字段作主键
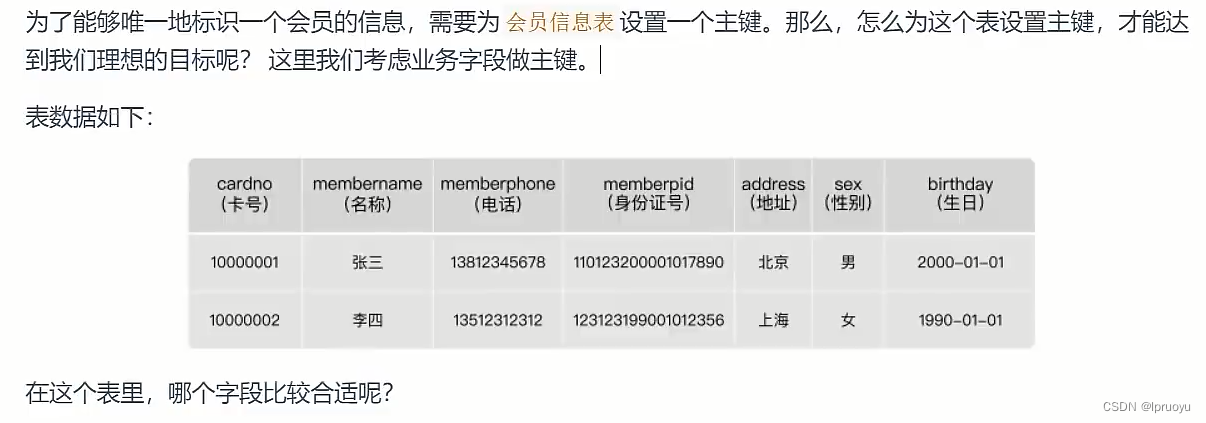
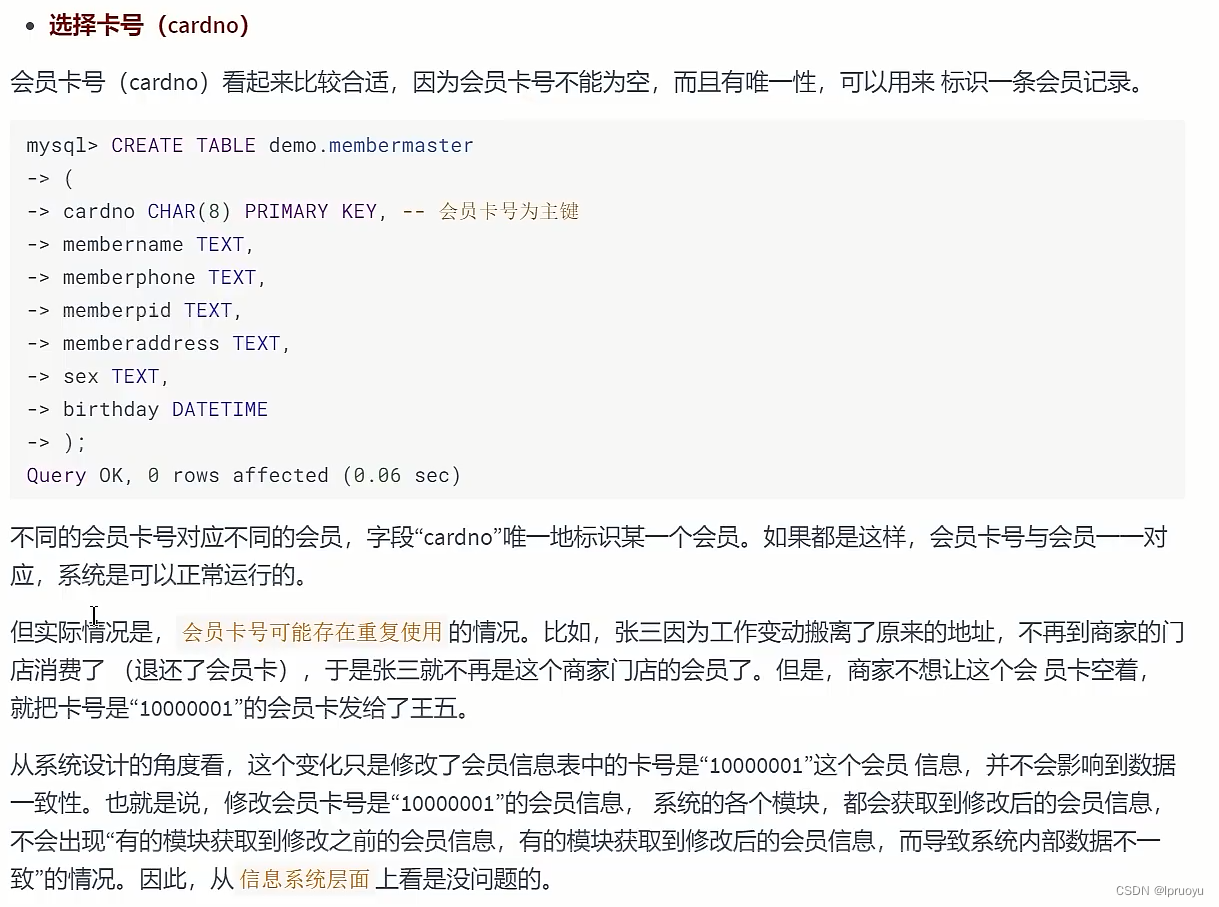
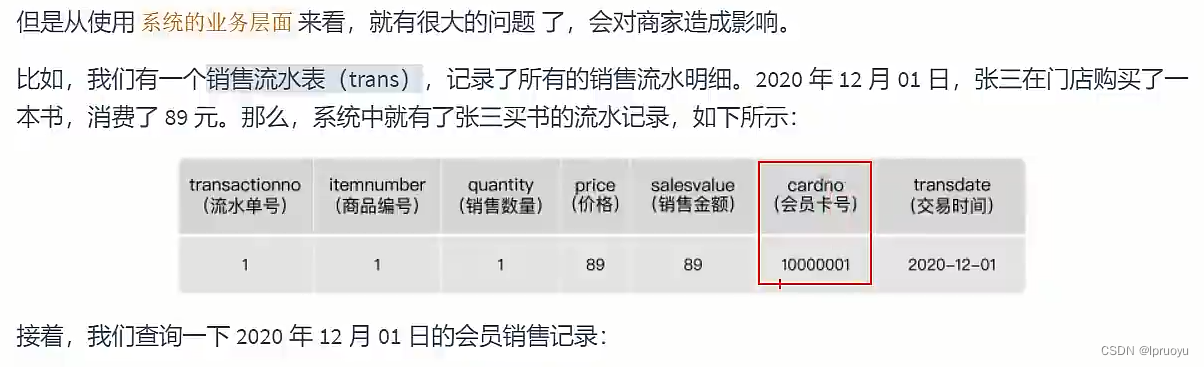
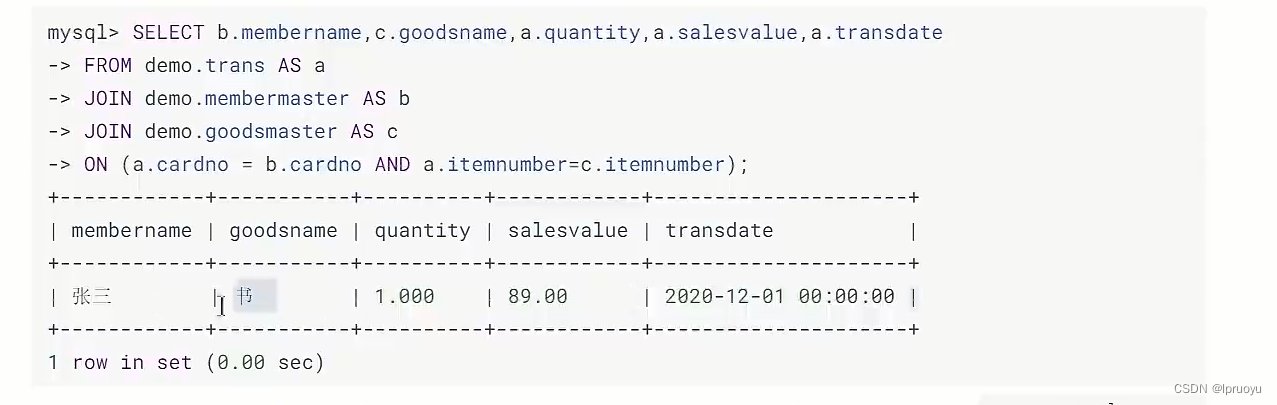


# 淘宝的主键设计

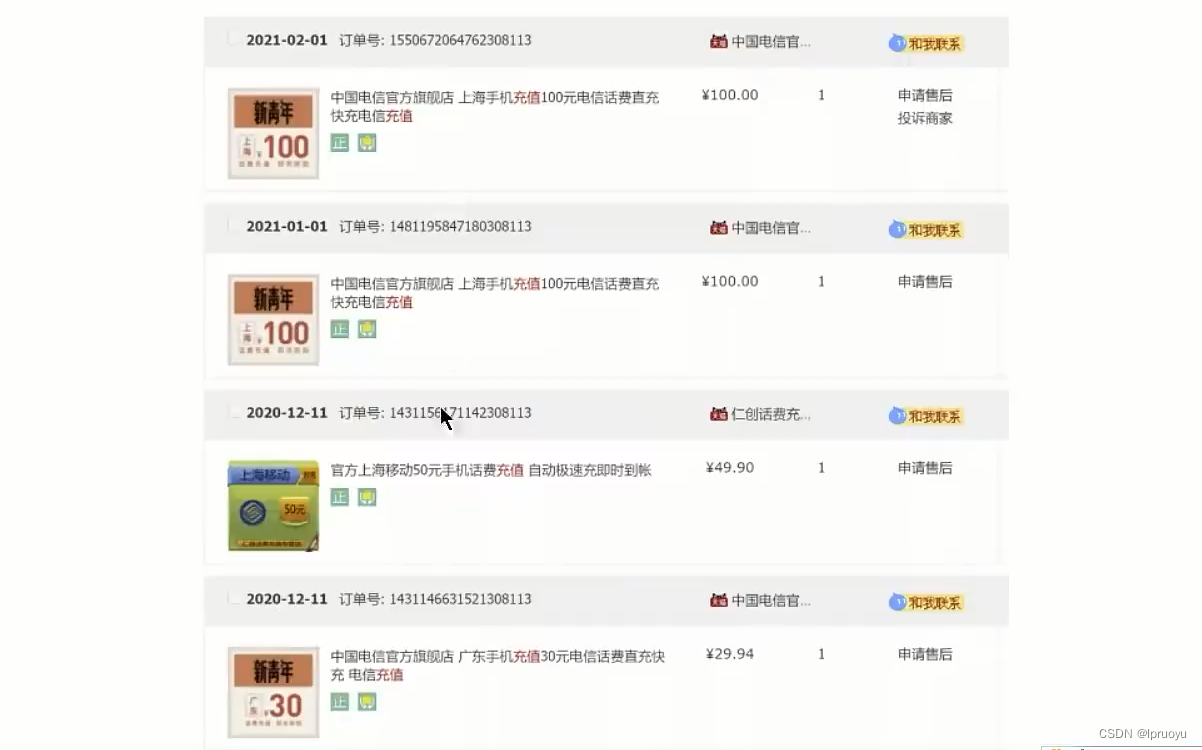
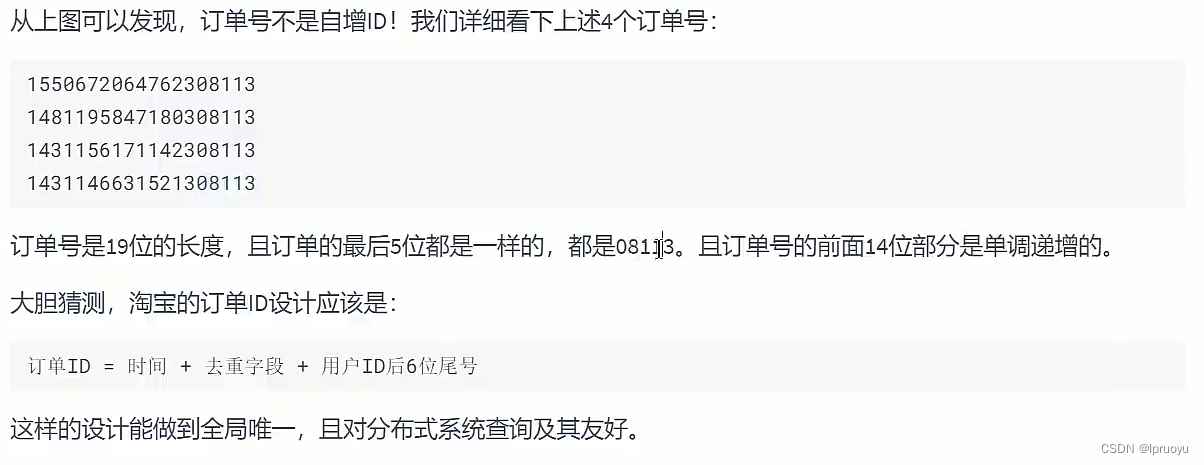
# 推荐的主键设计





SELECT UUID() FROM DUAL;
SET @uuid = UUID();
SELECT @uuid,uuid_to_bin(@uuid),uuid_to_bin(@uuid,TRUE);
1
2
3
4
5
2
3
4
5
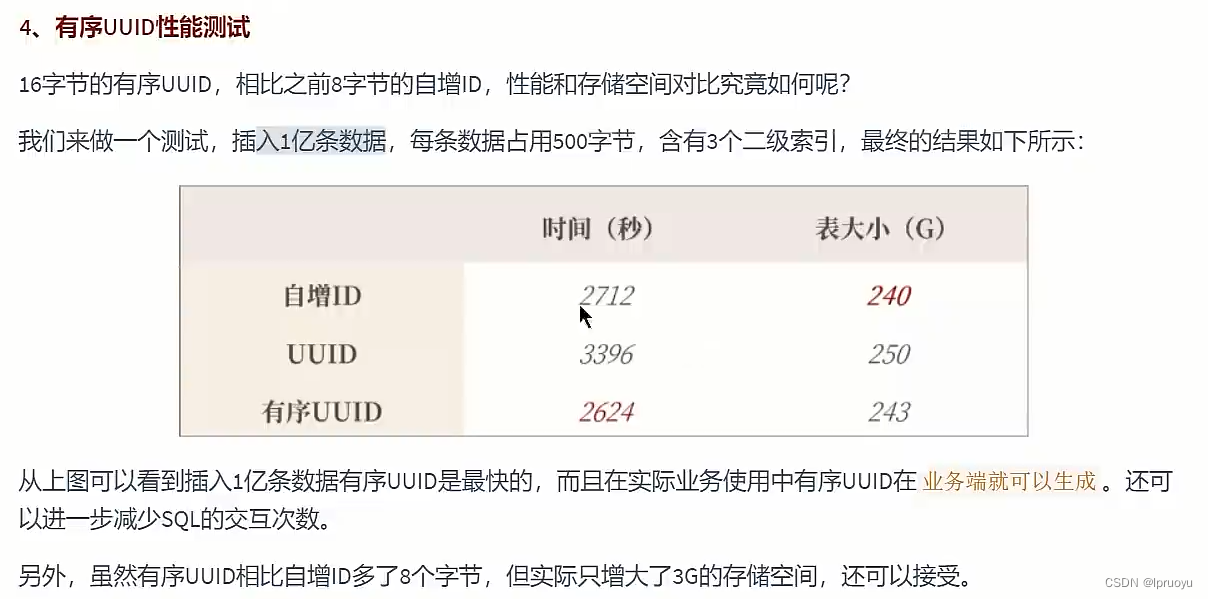


# 参考
编辑 (opens new window)
上次更新: 2024/01/26, 05:03:22
- 01
- python使用生成器读取大文件-500g09-24
- 02
- Windows环境下 Docker Desktop 安装 Nginx04-10
- 03
- 使用nginx部署多个前端项目(三种方式)04-10