 第30章【高级篇】数据库的设计规范
第30章【高级篇】数据库的设计规范
# 【宋红康 MySQL数据库 】【高级篇】数据库的设计规范
# 为什么需要数据库设计


# 范式
# 范式简介

# 范式都包括哪些

# 键和相关属性的概念


# 第一范式 (opens new window)

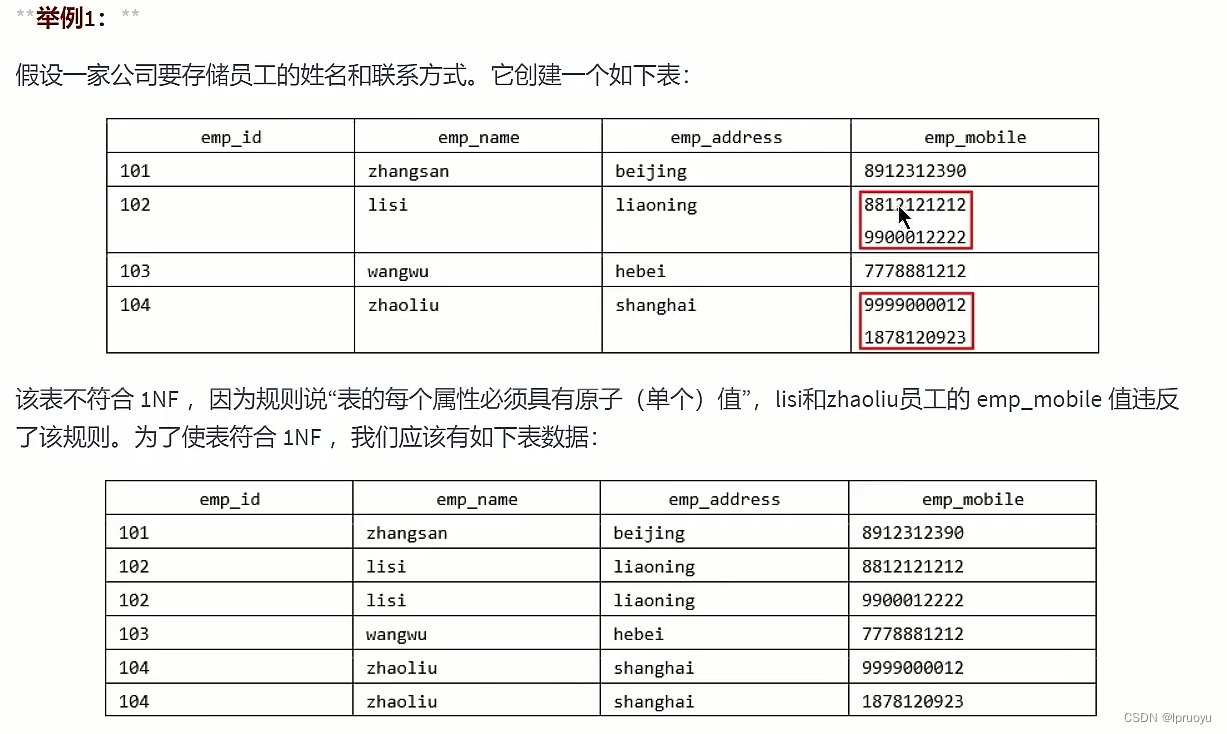
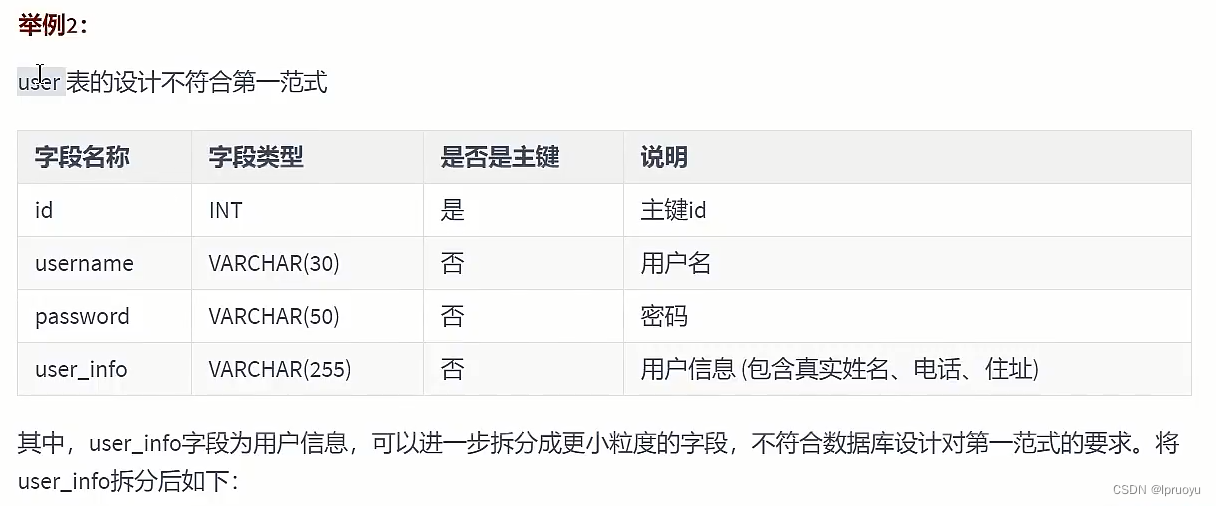
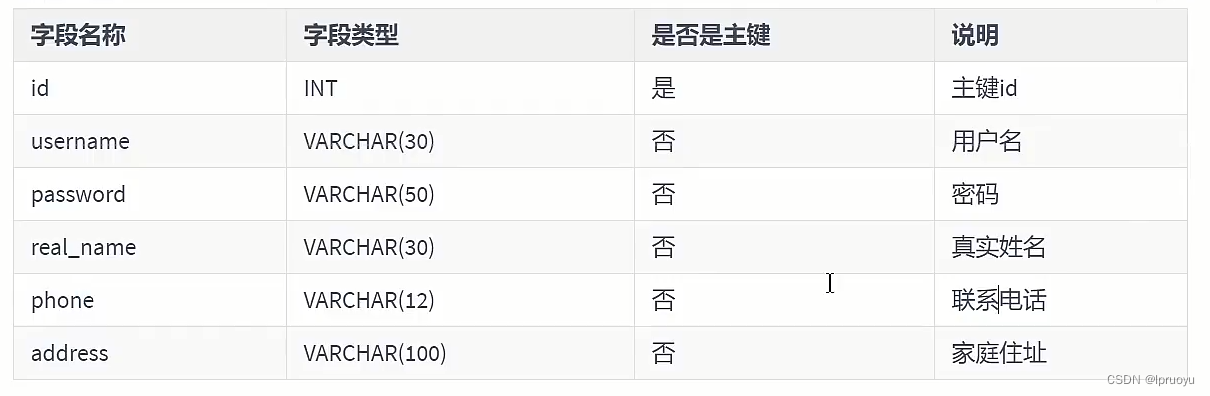
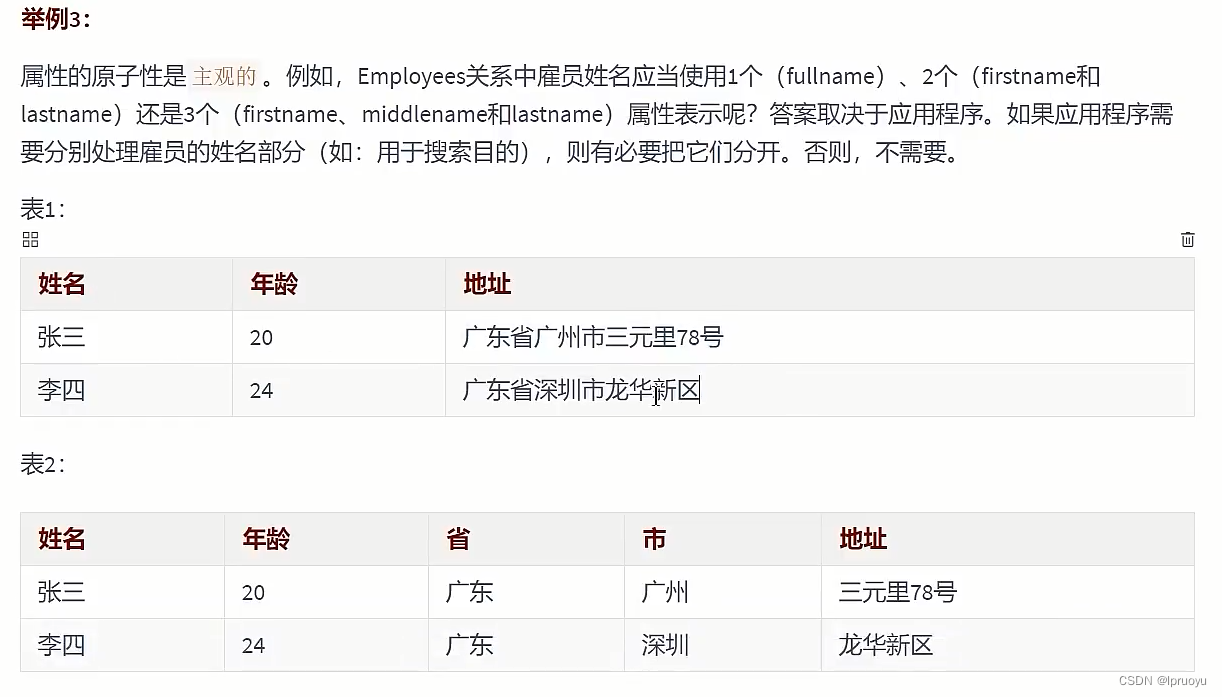
# 第二范式

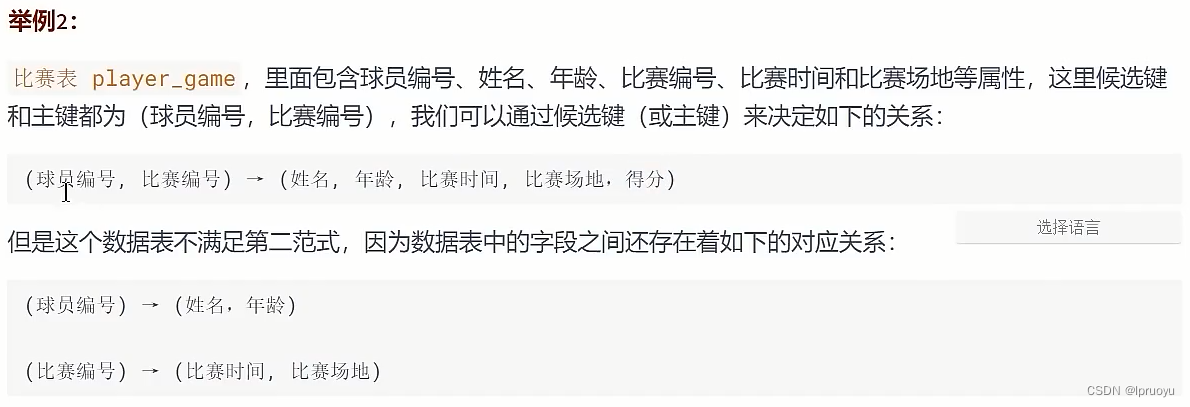




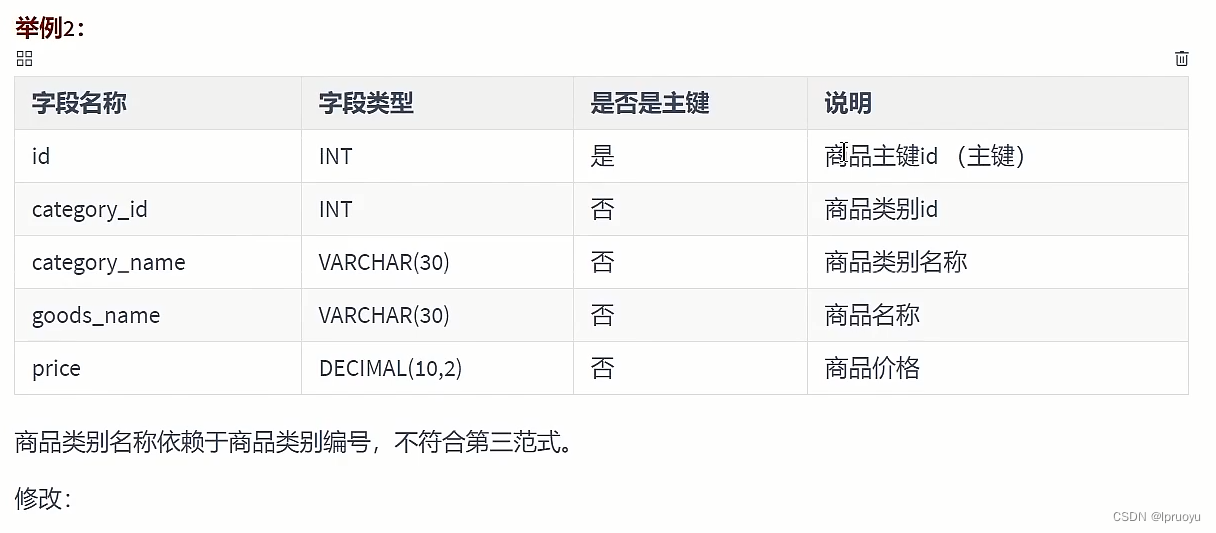
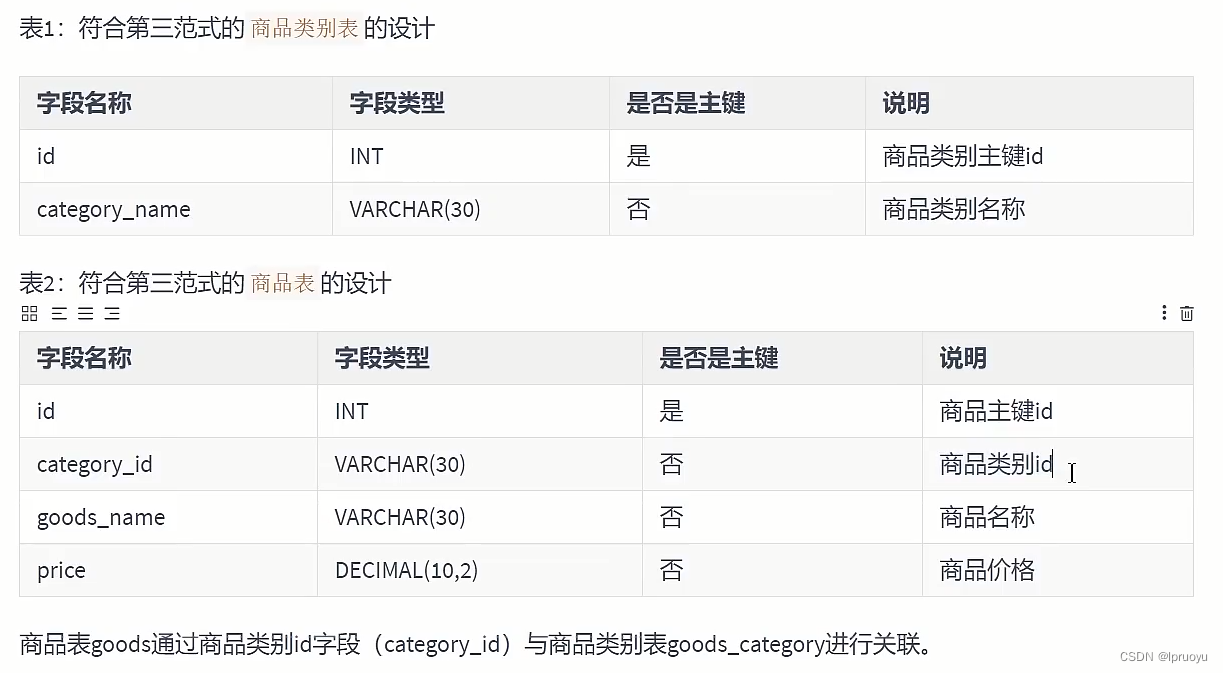
# 第三范式




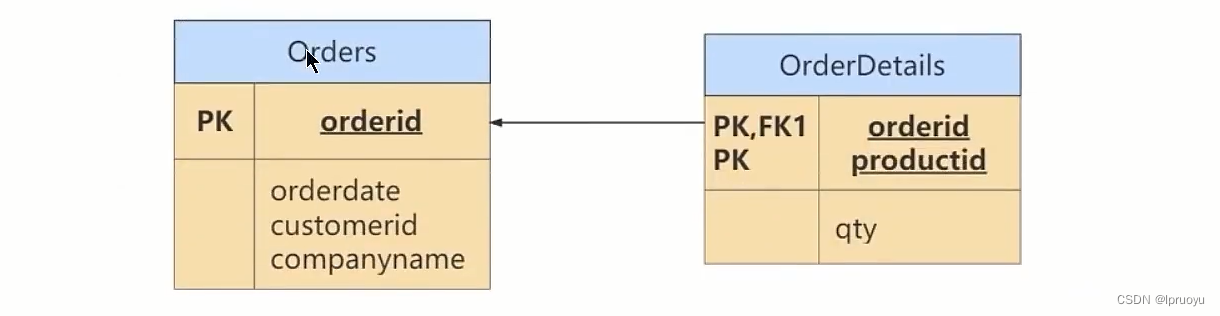
# 小结

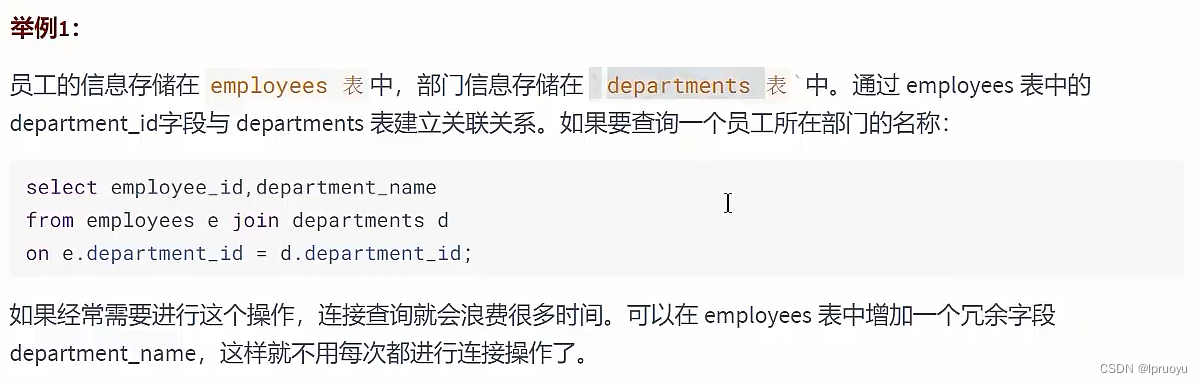
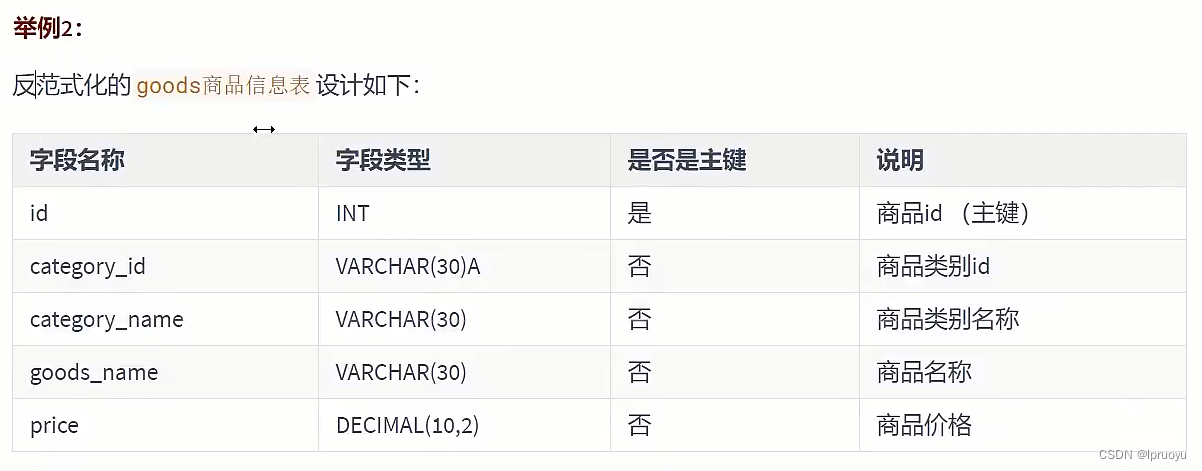
# 反范式化
# 概述


# 应用举例
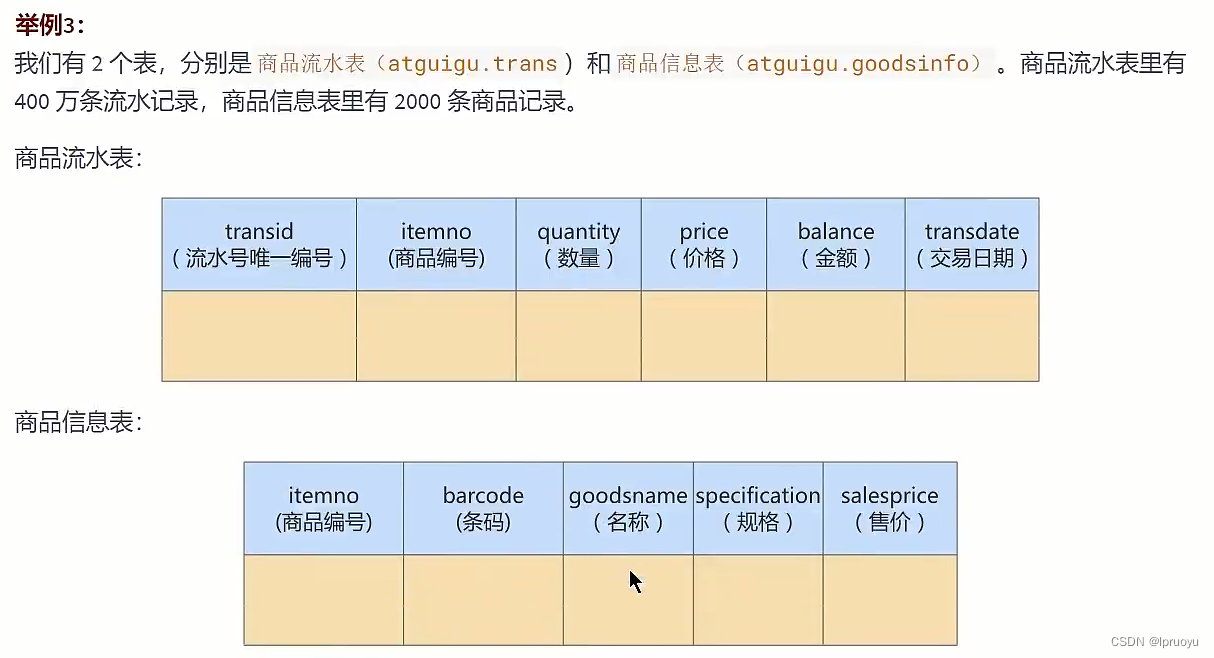
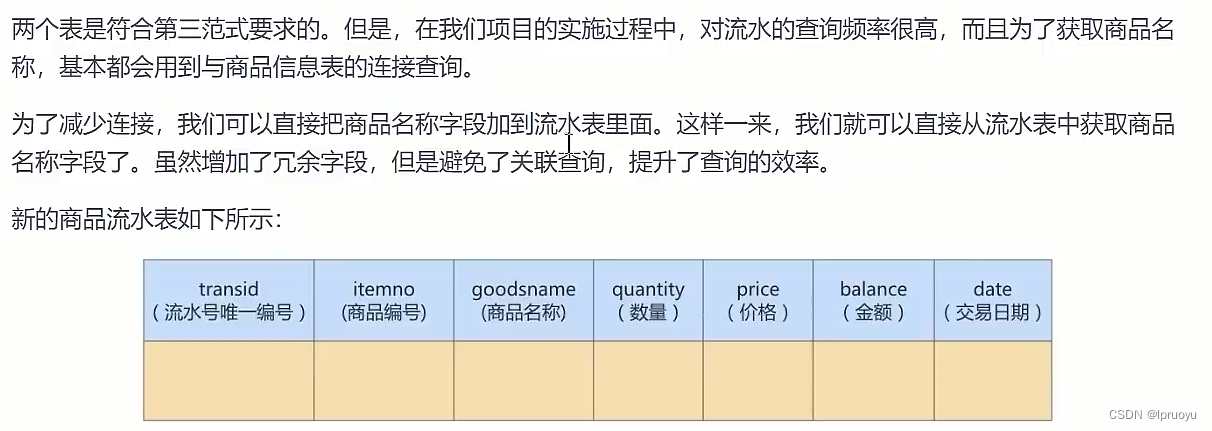


CREATE DATABASE atguigudb3;
USE atguigudb3;
#学生表
CREATE TABLE student(
stu_id INT PRIMARY KEY AUTO_INCREMENT,
stu_name VARCHAR(25),
create_time DATETIME
);
#课程评论表
CREATE TABLE class_comment(
comment_id INT PRIMARY KEY AUTO_INCREMENT,
class_id INT,
comment_text VARCHAR(35),
comment_time DATETIME,
stu_id INT
);
###创建向学生表中添加数据的存储过程
DELIMITER //
CREATE PROCEDURE batch_insert_student(IN START INT(10), IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE date_start DATETIME DEFAULT ('2017-01-01 00:00:00');
DECLARE date_temp DATETIME;
SET date_temp = date_start;
SET autocommit=0;
REPEAT
SET i=i+1;
SET date_temp = DATE_ADD(date_temp, INTERVAL RAND()*60 SECOND);
INSERT INTO student(stu_id, stu_name, create_time)
VALUES((START+i), CONCAT('stu_',i), date_temp);
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
#调用存储过程,学生id从10001开始,添加1000000数据
CALL batch_insert_student(10000,1000000);
####创建向课程评论表中添加数据的存储过程
DELIMITER //
CREATE PROCEDURE batch_insert_class_comments(IN START INT(10), IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE date_start DATETIME DEFAULT ('2018-01-01 00:00:00');
DECLARE date_temp DATETIME;
DECLARE comment_text VARCHAR(25);
DECLARE stu_id INT;
SET date_temp = date_start;
SET autocommit=0;
REPEAT
SET i=i+1;
SET date_temp = DATE_ADD(date_temp, INTERVAL RAND()*60 SECOND);
SET comment_text = SUBSTR(MD5(RAND()),1, 20);
SET stu_id = FLOOR(RAND()*1000000);
INSERT INTO class_comment(comment_id, class_id, comment_text, comment_time, stu_id)
VALUES((START+i), 10001, comment_text, date_temp, stu_id);
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
#添加数据的存储过程的调用,一共1000000条记录
CALL batch_insert_class_comments(10000,1000000);
#########
SELECT COUNT(*) FROM student;
SELECT COUNT(*) FROM class_comment;
###需求######
SELECT p.comment_text, p.comment_time, stu.stu_name
FROM class_comment AS p LEFT JOIN student AS stu
ON p.stu_id = stu.stu_id
WHERE p.class_id = 10001
ORDER BY p.comment_id DESC
LIMIT 10000;
#####进行反范式化的设计######
#表的复制
CREATE TABLE class_comment1
AS
SELECT * FROM class_comment;
#添加主键,保证class_comment1 与class_comment的结构相同
ALTER TABLE class_comment1
ADD PRIMARY KEY (comment_id);
SHOW INDEX FROM class_comment1;
#向课程评论表中增加stu_name字段
ALTER TABLE class_comment1
ADD stu_name VARCHAR(25);
#给新添加的字段赋值
UPDATE class_comment1 c
SET stu_name = (
SELECT stu_name
FROM student s
WHERE c.stu_id = s.stu_id
);
#查询同样的需求
SELECT comment_text, comment_time, stu_name
FROM class_comment1
WHERE class_id = 10001
ORDER BY comment_id DESC
LIMIT 10000;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117

# 反范式的新问题

# 反范式的适用场景



# 巴斯范式






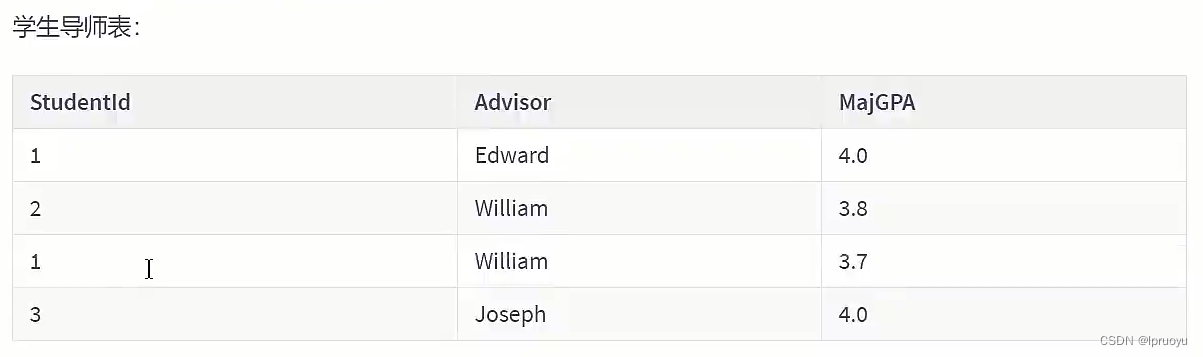
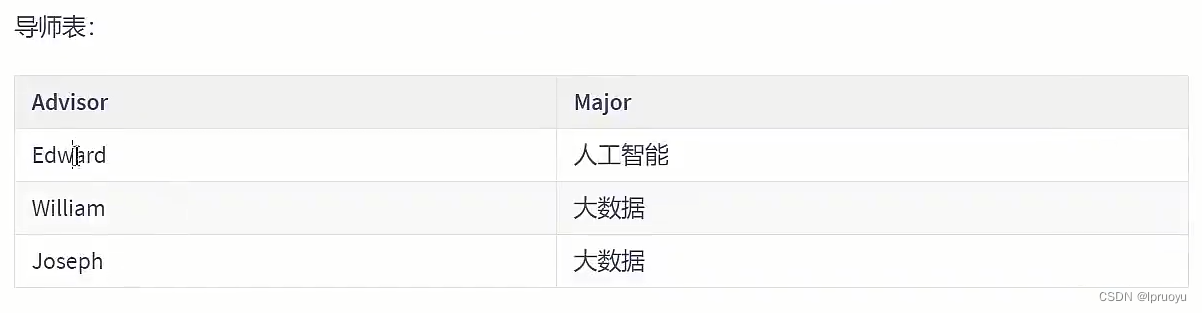
# 第四范式


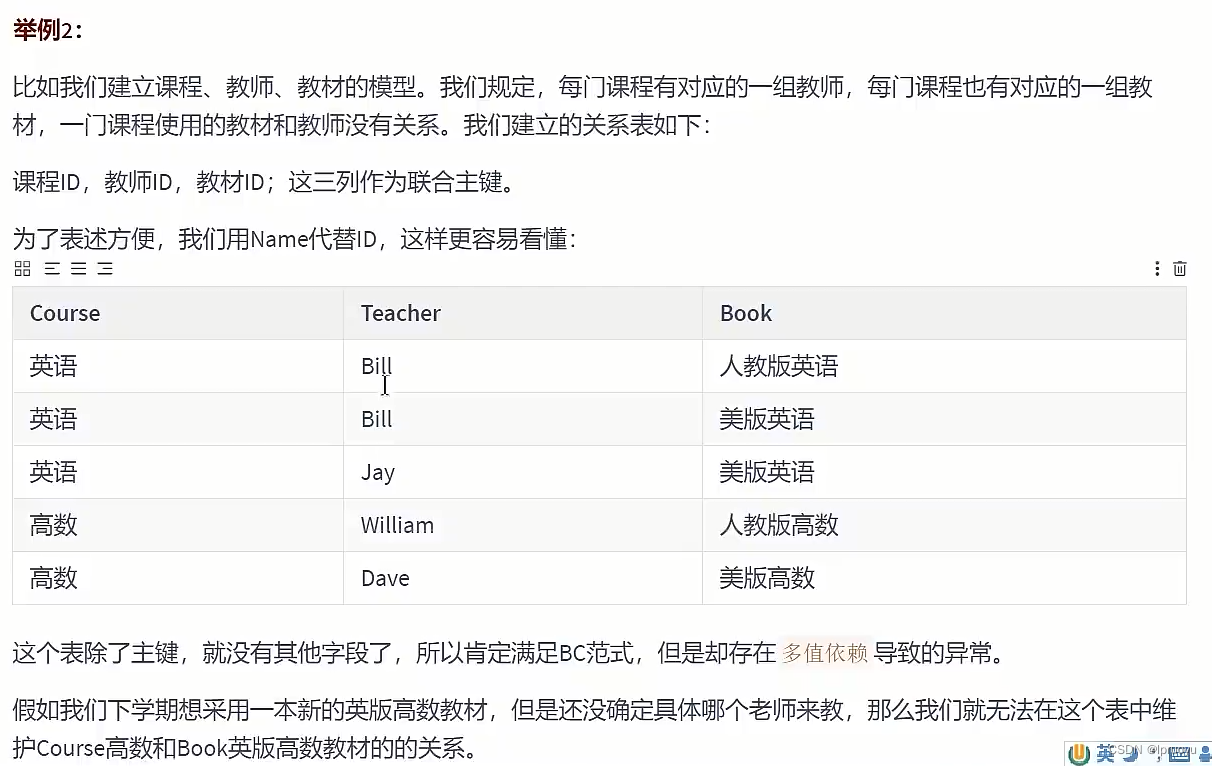
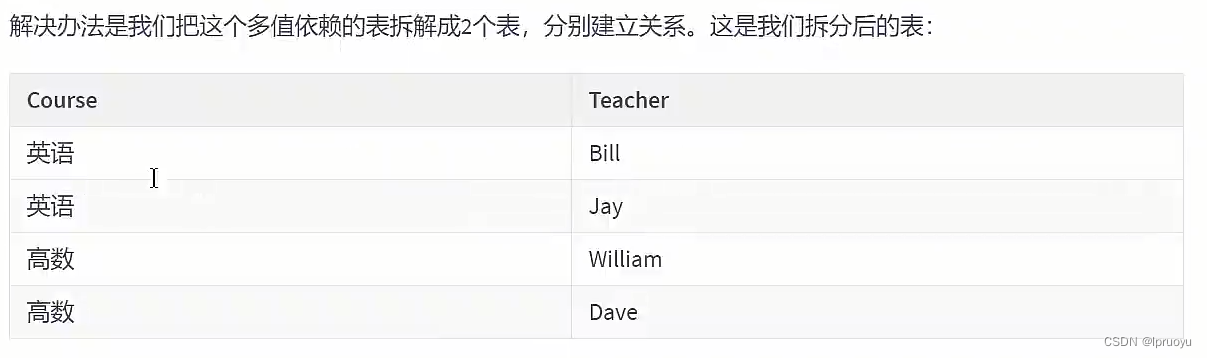
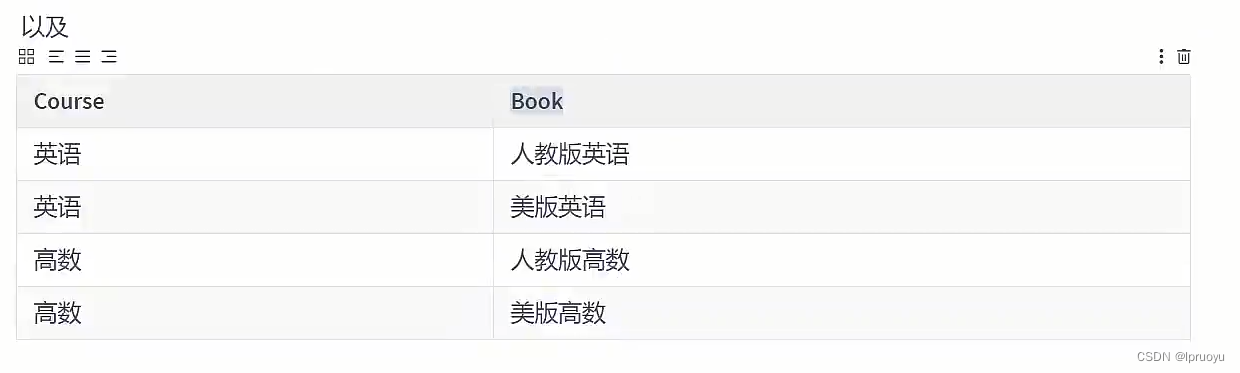
# 第五范式、域键范式

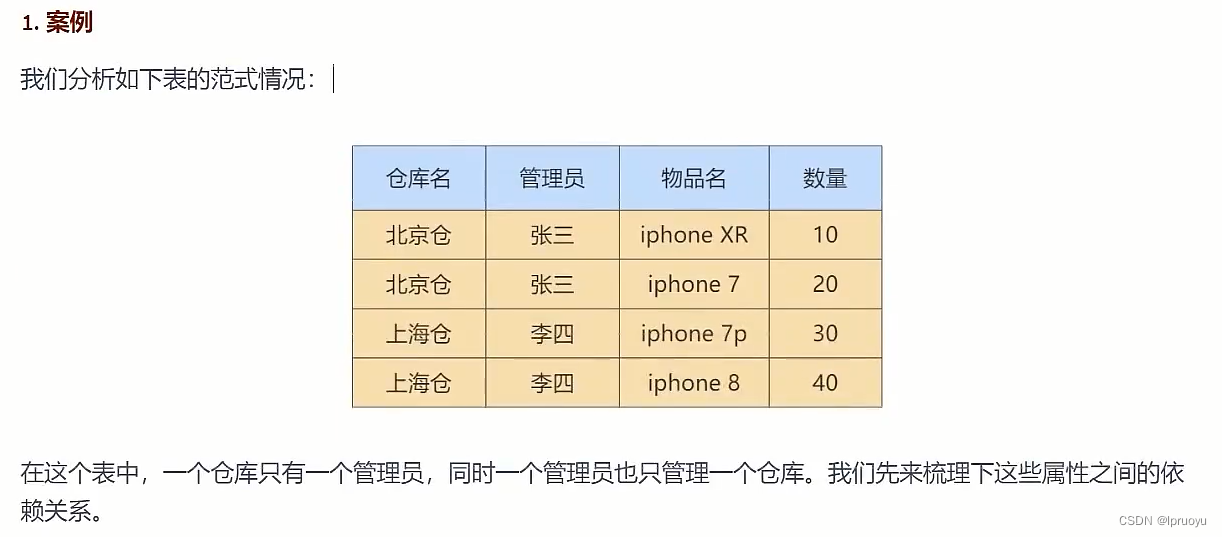
# 实战案例
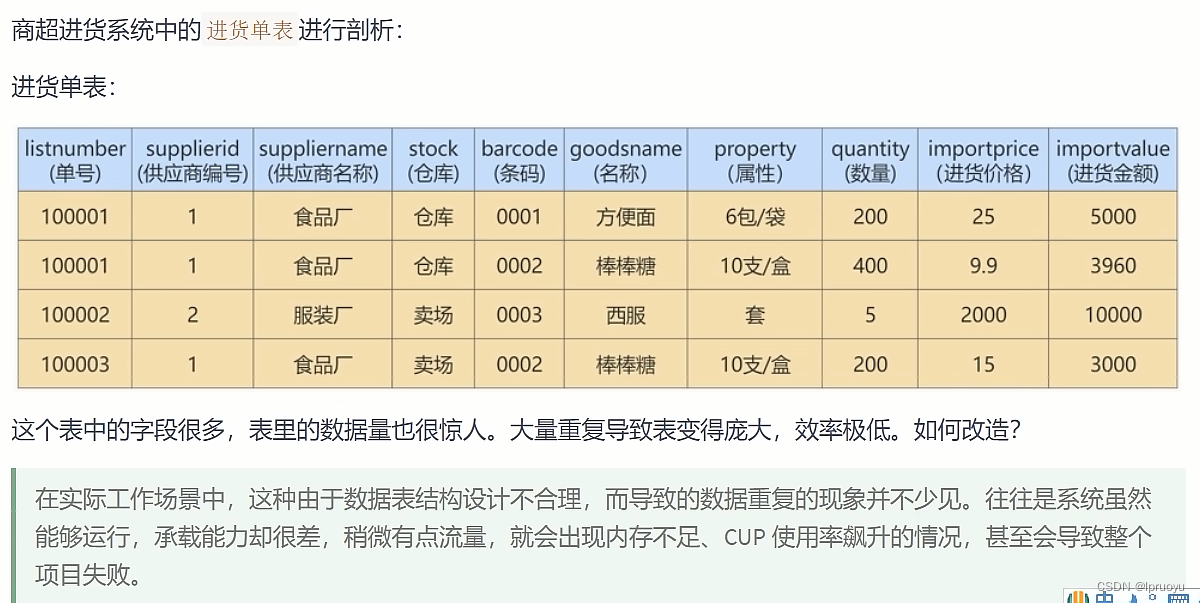
# 迭代1次:考虑1NF
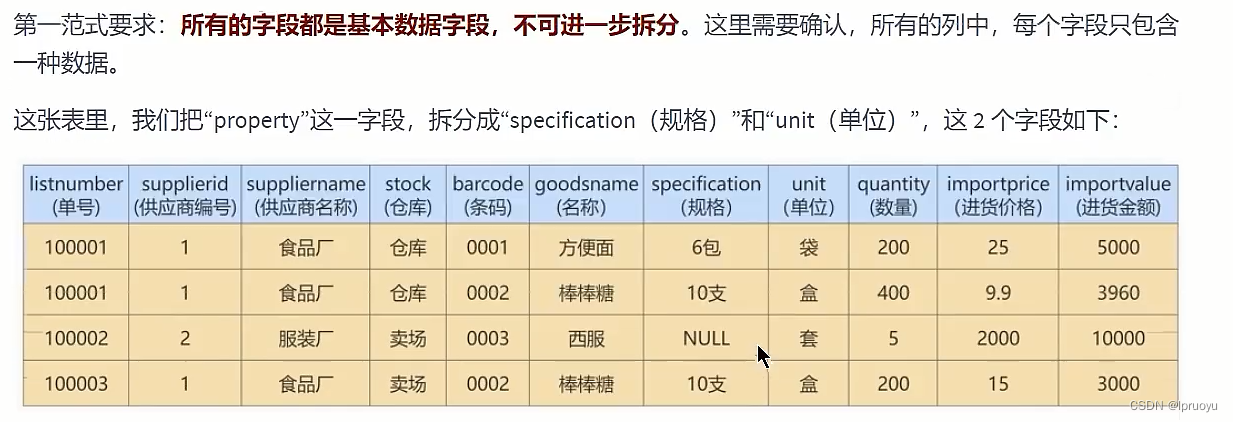
# 迭代2次:考虑2NF

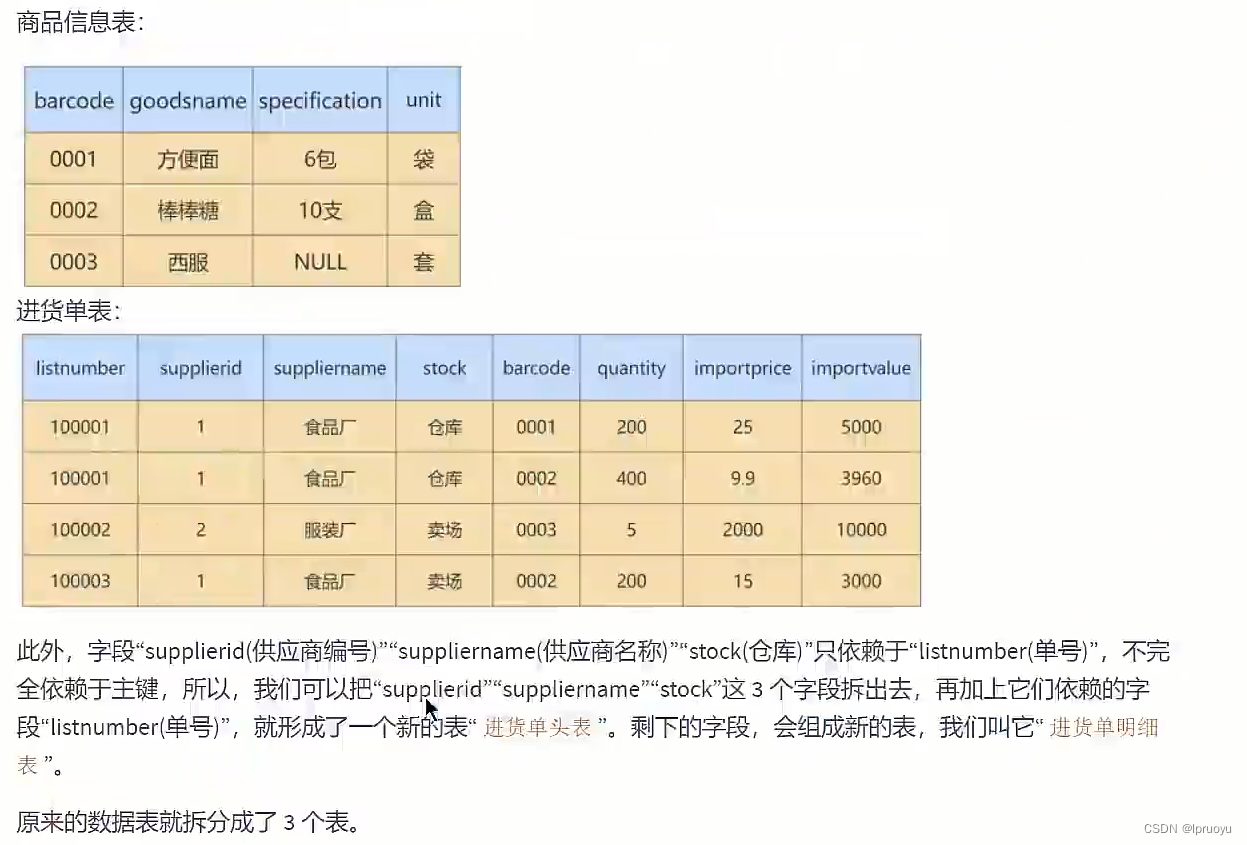
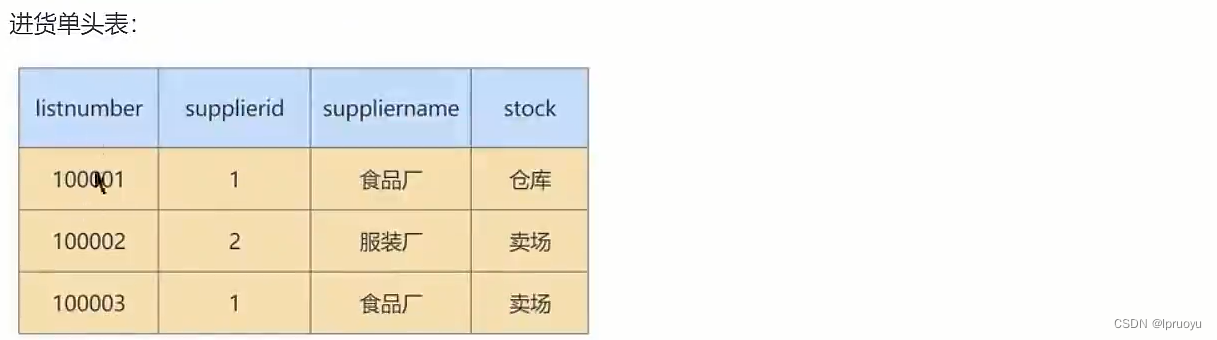
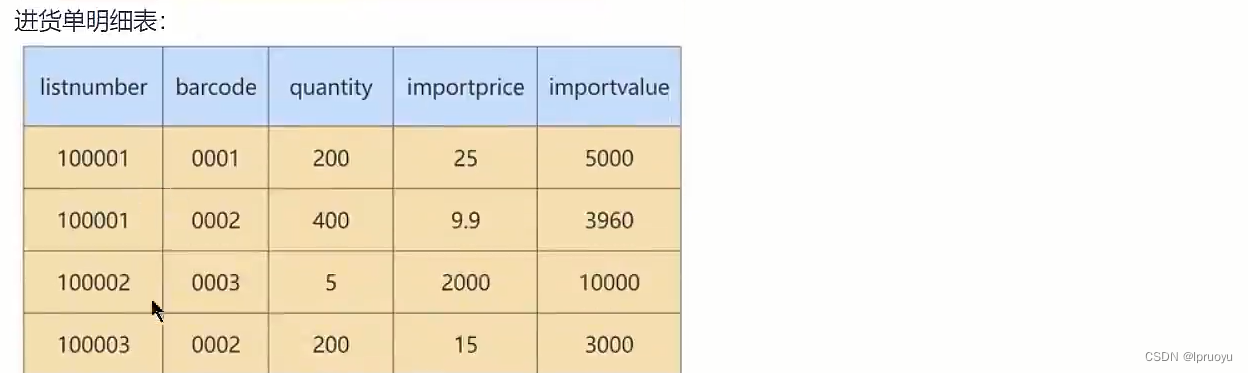
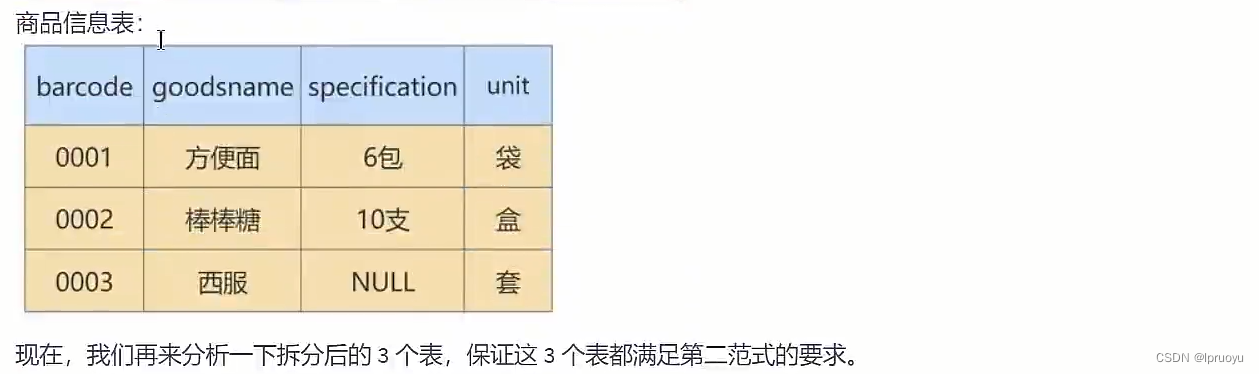

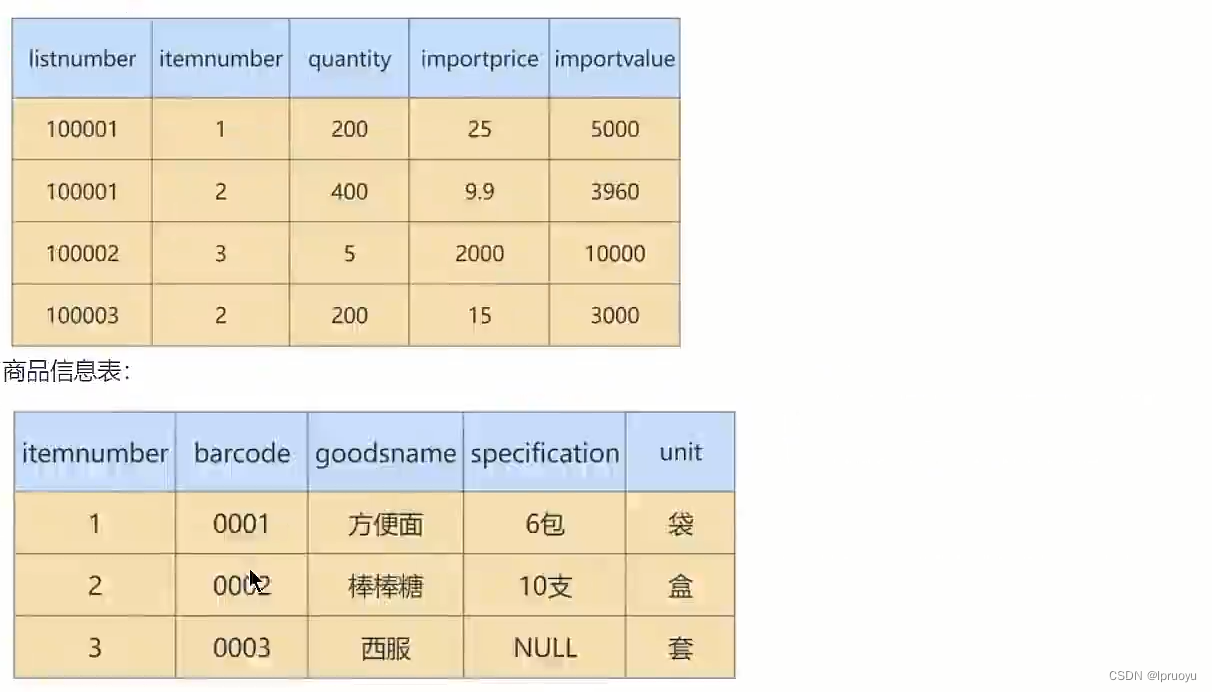

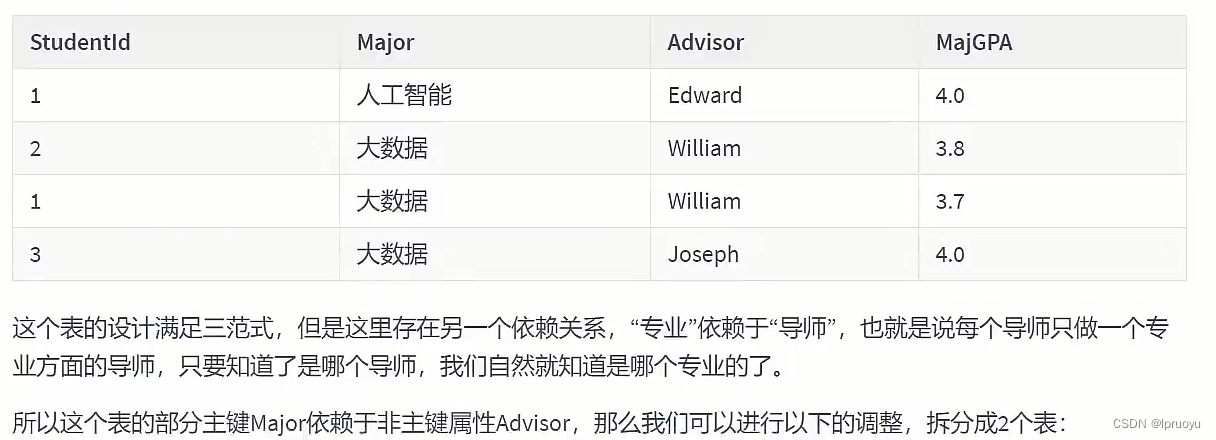
# 迭代3次:考虑3NF
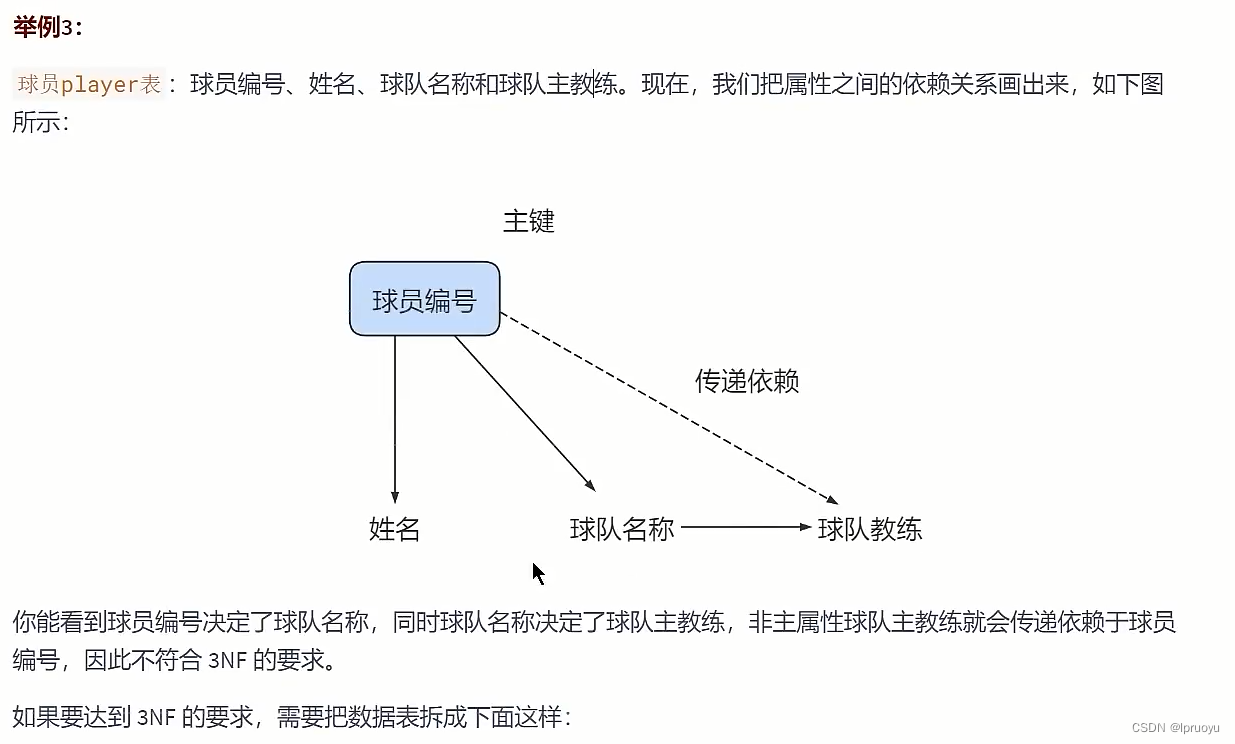
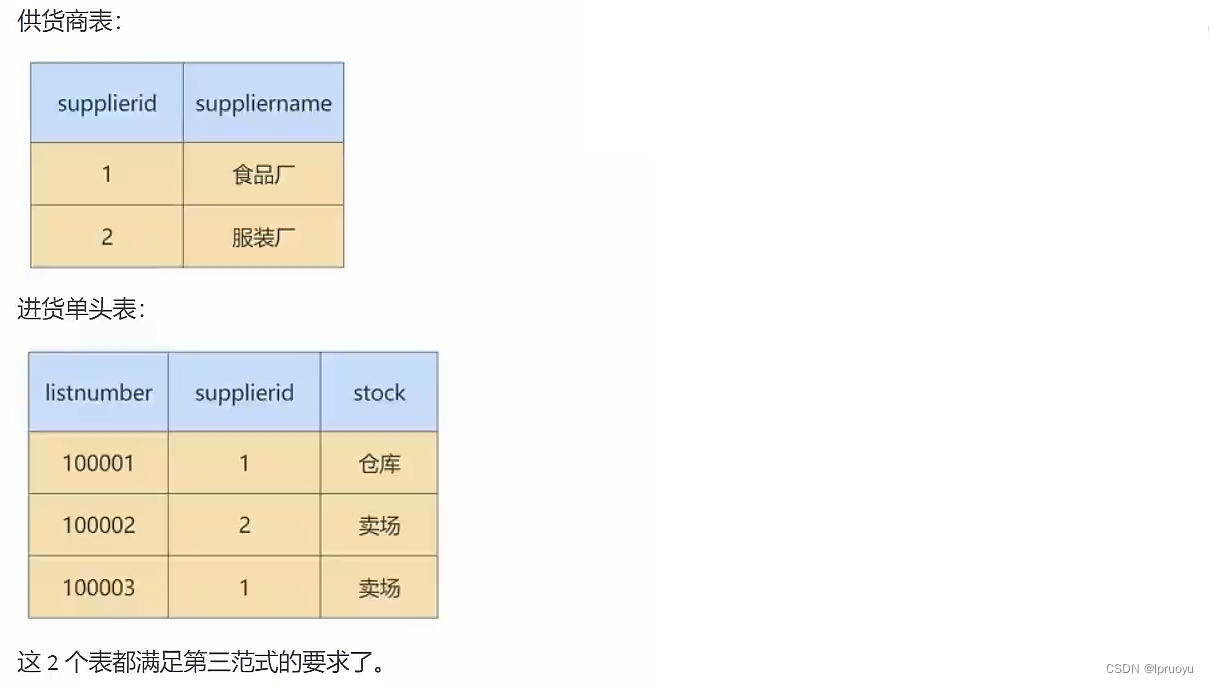
我们的进货单头表,还有数据冗余的可能。因为“suppliername”依赖“supplierid”,那么,这个时候,就可以按照第三范式的原则进行拆分了。我们就进一步拆分下进货单头表,把它解析成供货商表和进货单头表。
# 反范式化:业务优先的原则

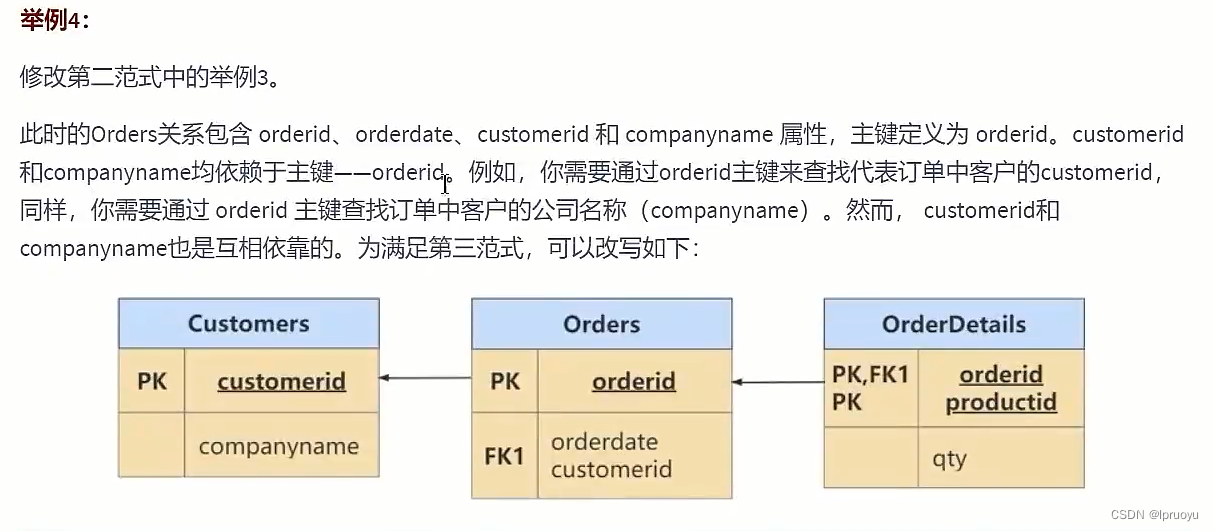
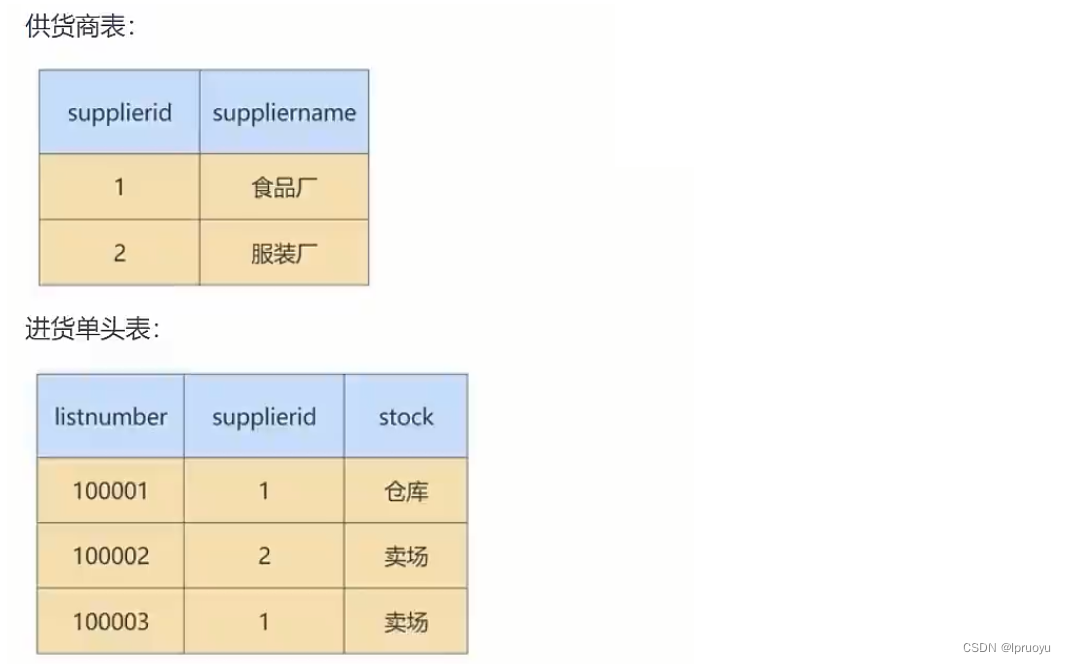
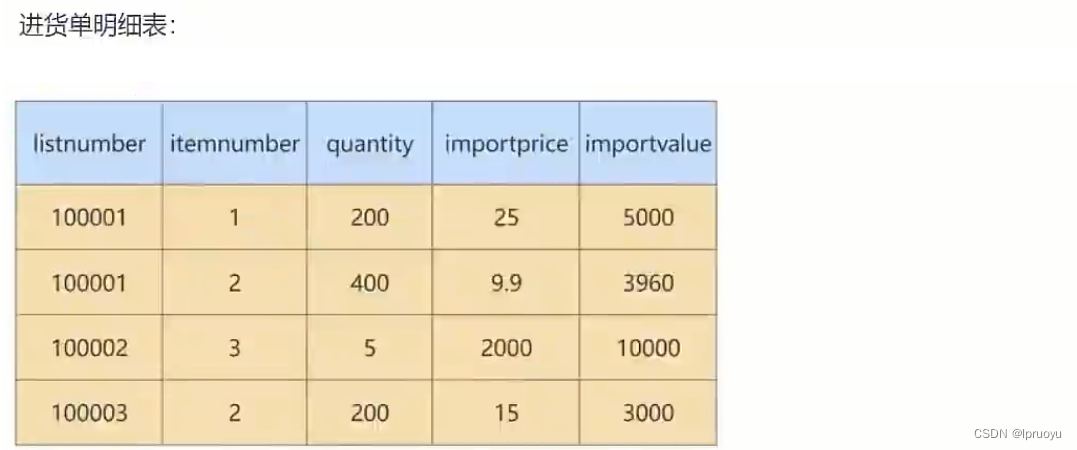
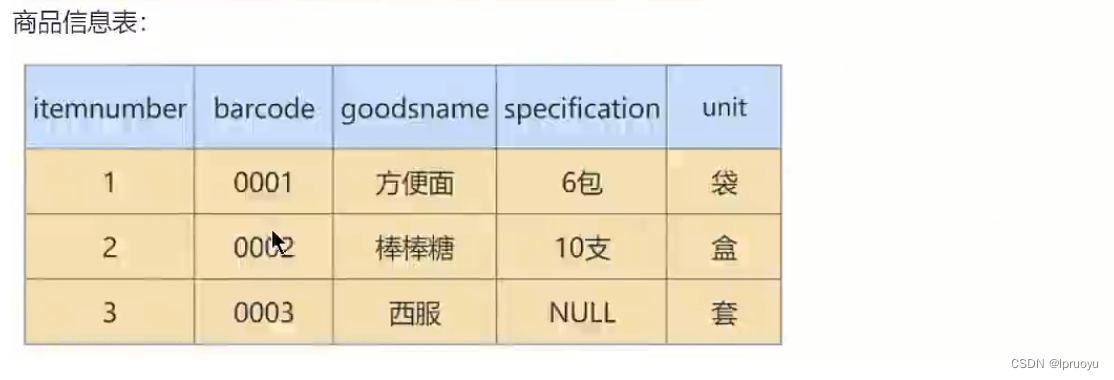
所以最终就被拆分成了下面四张表:
# ER模型

# ER模型包括哪些要素

# 关系的类型

# 建模分析


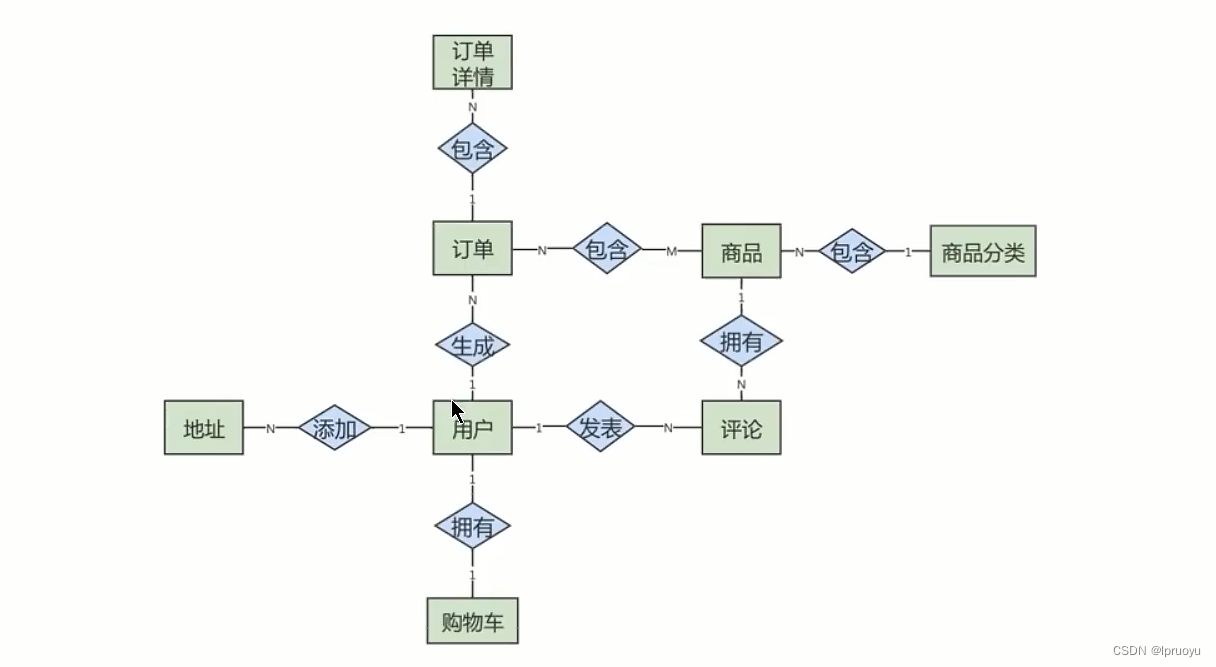

# ER模型的细化


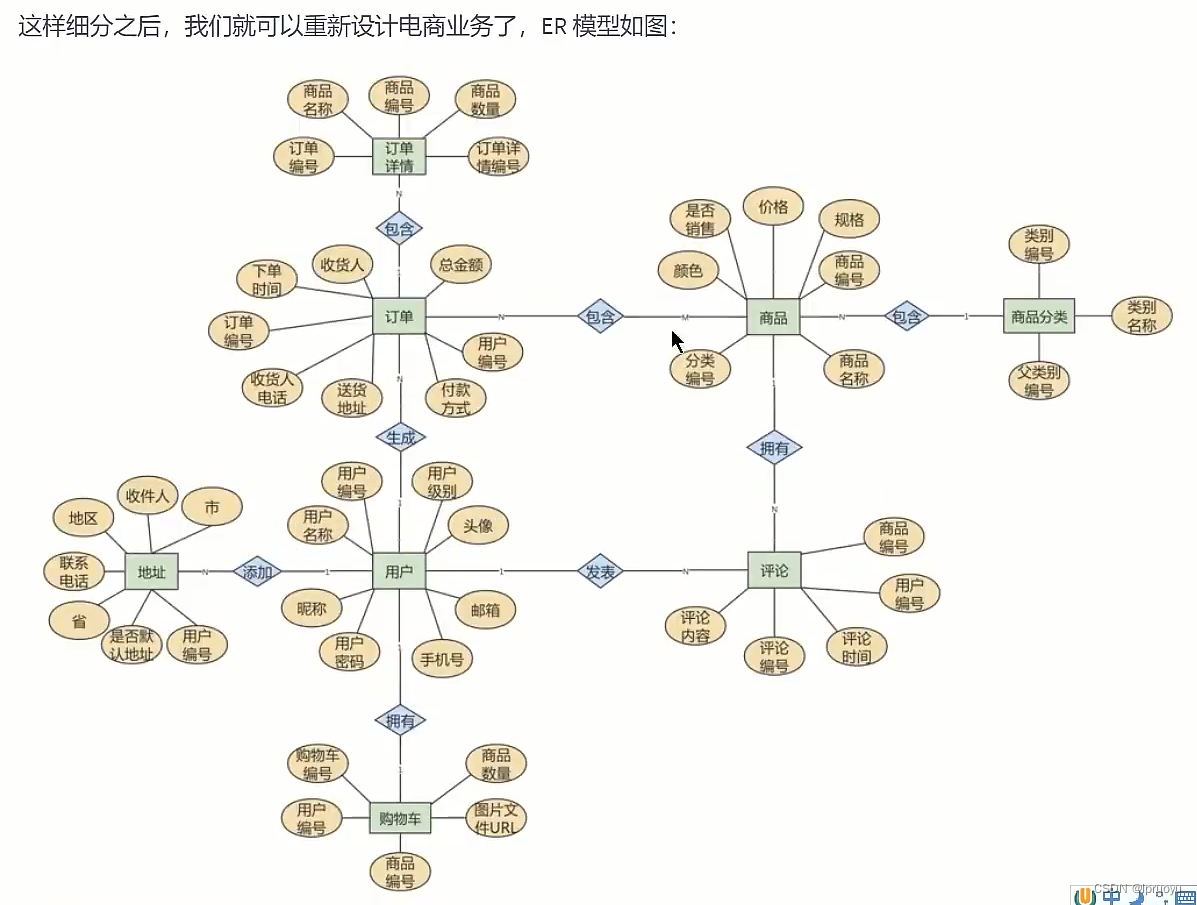
# ER模型转化为数据表

值得注意的是:

还有:
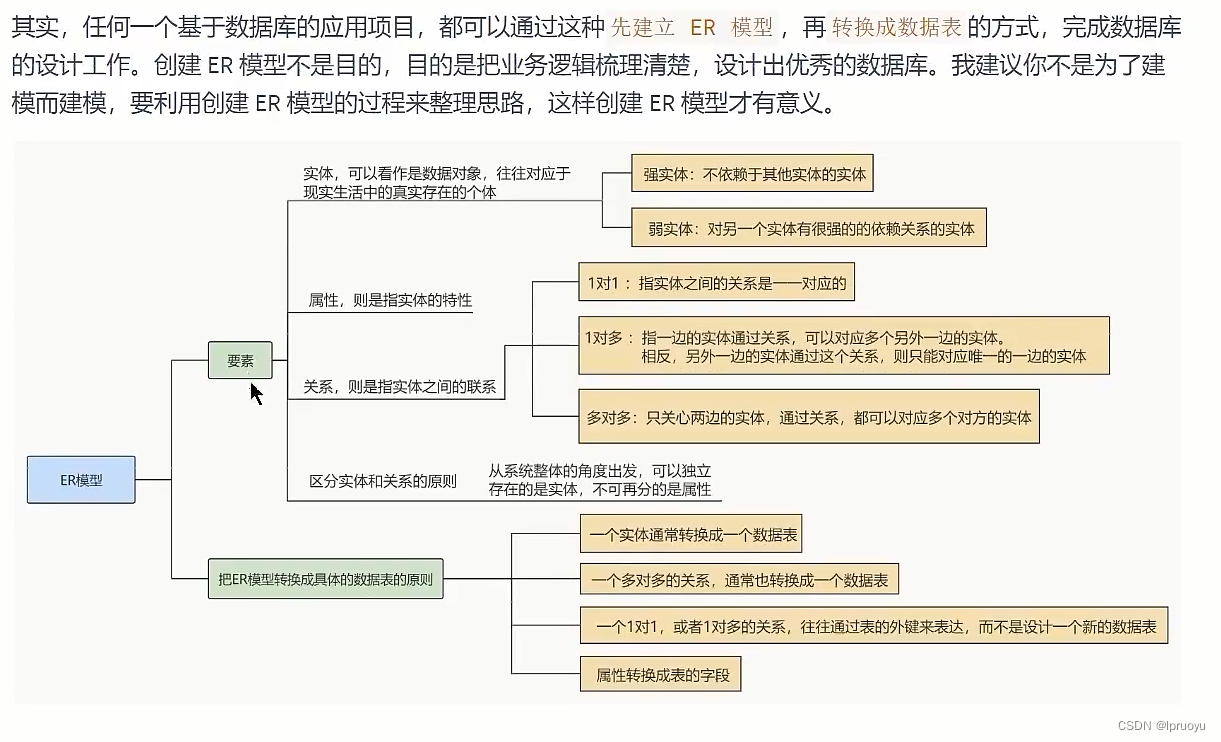
# 数据表的设计原则


# 数据库对象编写建议

# 关于库

# 关于表、列



# 关于索引

# SQL编写


编辑 (opens new window)
上次更新: 2024/01/26, 05:03:22
- 01
- python使用生成器读取大文件-500g09-24
- 02
- Windows环境下 Docker Desktop 安装 Nginx04-10
- 03
- 使用nginx部署多个前端项目(三种方式)04-10